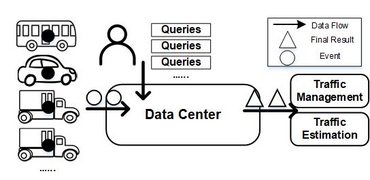
We now present Destream a decentralized aggregation technique that can process multiple ad-hoc queries in decentralized networks. There are two kinds of ad-hoc queries: long continuous queries and short continuous queries. Long continuous queries contain many windows and they output results periodically. Short continuous queries openly have one window, and system drop queries once results are generated. To avoid redundant computations between concurrent windows, we use window slicing. It reuses partial results of each overlap instead of processing all windows individually. This technique not only improves the performance of our system but also reduces the consumption of computational resources. Before describing our approach, we defined the terms query-group and punctuation.
Query-Group: the query-group is a set of queries that partial results can be shared between. For multiple queries, current systems need to create separate windows to process events. Our aggregation engine puts queries that can be shared into one query-group and produces slices instead of windows. For queries that have different selection predicates, they can be put into the same query-group since there are overlaps between their windows. Also, different query-groups are processed separately and Desis needs to maintain the context of each groups, i.e., the list of slices and aggregation operators.
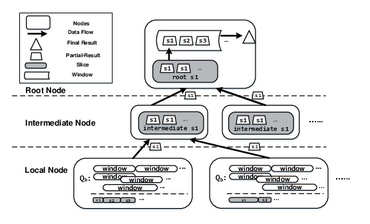
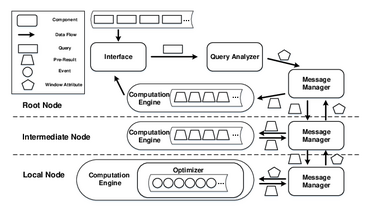
In a decentralized setup, there are local nodes, intermediate nodes, and one root node in topology. Local nodes can connect to the root node directly or via intermediate nodes. For complex networks, more intermediate nodes are interconnected between the local and root nodes, and there are more hops from a local node to the root node. Compared to centralized aggregation, our system can execute aggregation on local nodes and intermediate nodes. It can dramatically minimize the data amount sent by each node and reduce aggregation steps done on the root node. In the following discussion, we discuss decentralized aggregation that processes different selection predicates, window types, window measures and aggregation functions.
In figure, we show three example queries and they are all time-based, Qa has tumbling windows and executes sum functions. Its selection predicate is speed > 50. Qb and Qc execute average functions and they have sliding and user-defined windows. Their selection predicates are speed > 25 and speed > 75, respectively. In the root node, the system puts Qa, Qb, and Qc into a query-group and outputs window attributes. All windows produced from that query-group can be shared, as they have overlaps. Then, the message manager distributes the window attributes of this query-group to local and intermediate nodes. On a local node, the aggregation engine splits windows into local slices according to the window attributes that are received from the root node. Then, the aggregation engine executes incremental aggregations for every event. Otherwise, the aggregation engine may get stuck since it has to spend a long time iterating and computing all events in the slice. Once a local slice ends, the aggregation engine executes its aggregation functions and transmits partial results to the intermediate nodes. Also, if a local slice is ended by an end punctuation (ep), the system will mark this slice with the ep. On an intermediate node, our system creates an intermediate slice and collects partial results from its child nodes for this slice. When the intermediate slice receives all results from local nodes, it calculates partial results and sends them to the root node. If partial results from local nodes are marked with a ep, the intermediate partial result will keep this ep. Similar to local nodes, we also perform incremental aggregations on intermediate nodes. For example, in figure, when there are two partial results of s1, they are collected to the intermediate slice (s1). On the root node, partial results from its child nodes are gathered and incrementally calculated into a root slice. When a slice ends, the aggregation engine executes aggregation functions and saves its result. If intermediate partial results carry an ep, the aggregation engine has to assemble all partial results belonging to this window and output the final result. In figure, we terminate the root slice (s1) when both partial results of intermediate s1 arrived. The partial result of intermediate s3 carries an ep}, and the root node ends the window according to this ep.