Der Balken beschreibt deinen Fortschritt beim Lösen aller Aufgaben. Schaffst du es, alle Fragen richtig zu beantworten?
Text-Legende
Hervorhebung im Text
Erklärung
Begriff
Begriffs-Definition/-Einführung
Begriff
Extra Erläuterung als Popup
Ausdruck
Quelltext oder Zeichenkette
Aufgaben-Legende
Alle Feedbacks, die für eine deiner Lösungen bekommen kannst. Zum abschicken der Lösung musst du davor auf Lösungen überprüfen drücken.
Eingabefeld
Feedback
Richtige Antwort
Bisher noch keine Eingabe oder falsches Eingabeformat
Falsche Lösung, vielleicht auch falsches Eingabeformat.
Impressum
Für das allgemeine Impressum, siehe HPI-Impressum.
Die vorliegende Lehrwebsite entstand im Rahmen eines Projekts des Moduls Algorithmen und Datenstrukturen an der FSU-Jena. Als Vorbild, was den Aufbau der Themen, einzelne Definitionen sowie Terminologie angeht, diente Reinhard Diestels Graphentheorie (Elektronische Ausgabe 2000, Springer). Sollten etwaige Fehler auftreten oder Fragen bestehen, wenden Sie sich bitte an dennis.kerzig[at]uni-jena.de. Im folgenden noch eine kurze Übersicht genutzter Frameworks und Bibliotheken:
Zum ersten mal da? Hinweise zur Benutzung der Website findest du unter dem -Symbol rechts oben. Am besten du nutzt zum Einarbeiten in das Themengebiet auch weiterführende Literatur, siehe dazu das -Symbol.
1. Das Haus vom Nikolaus
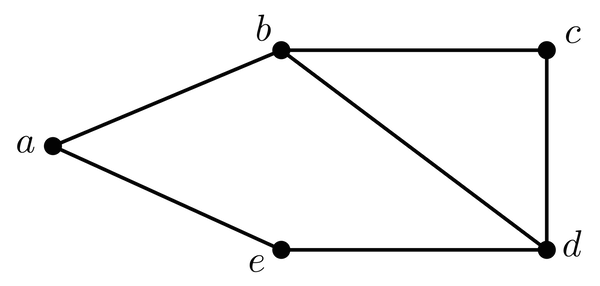
Das Haus vom Nikolaus als Graph $$N = (V,E)$$ mit $$V=\{a,b,c,d,e\}$$.
Sicher hat jeder von euch schonmal versucht das Haus vom Nikolaus auf einem Blatt Papier zu zeichnen. Natürlich ohne zwischendurch abzusetzen oder eine Kante mehrfach zu zeichnen, doch funktioniert das, egal bei welcher Ecke man anfängt? Und wieso geht das plötzlich nicht mehr, wenn der Nikolaus sein Haus um einen Anbau erweitert? Zur Formalisierung und Lösungsfindung solcher und vieler weiterer Probleme, wie der Routenplanung, Landkartenfärbung und Flussoptimierung, bietet sich ein Teilgebiet der Mathematik besonders an - Die Graphentheorie.
Im Folgenden führe ich den Grundbegriff eines Graphen ein und nenne wichtige Eigenschaften und Operationen. Ein Graph $$G$$ ist ein Tupel aus der Menge seiner Knoten $$V(G)$$ und Kanten $$E(G)$$, welche man auch explizit mit $$G=(V,E)$$ benennen kann. Die Kanten ungerichteter Graphen setzen sich aus 2-elementigen, verschiedenen Teilmengen der $$v \in V$$ zusammen. Klein $$n$$ steht für die Anzahl aller Knoten $$|V|$$ und $$m$$ analog für $$|E|$$. Enthält $$E$$ alle $$n(n-1) / 2$$ möglichen Teilmengen nennt man $$G$$ einen vollständigen Graphen $$K^n$$. Zwei Knoten $$v_1$$ und $$v_2$$ nennt man benachbart bzw. adjazent, wenn für die verbindene Kante $$\{v_1,v_2\} \in E$$ gilt. Die Knoten $$v_1$$ und $$v_2$$ nennt man dann ebenfalls inzident zur Kante $$\{v_1,v_2\}$$, weil diese jeweils einen Endpunkt in ihnen hat.
Die Anzahl aller inzidenten Kanten eines Knotens $$v$$ nennt man den Knotengrad bzw. $$d_G(v)$$. Der maximale Knotengrad $$\Delta(G)$$ bezeichnet den Knotengrad des Knotens mit den meisten inzidenten Kanten. Analog ist der minimale Knotengrad als $$\delta(G)$$ definiert.
Wähle einen Teilgraph, um die Veränderungen zum obigen Ausgangsgraphen $$T$$ zu sehen.
Im Kontext eines Graphen $$G$$ werden herkömmliche Mengenoperationen, wie sie z.B. bei den Mengen $$V$$ oder $$E$$ Anwendung finden, erweitert und abgekürzt. Anstatt explizit der Knotenmengen eines Graphen einen entsprechenden Knoten hinzuzufügen, schreibt man auch $$G \cup \{v\}$$ oder $$G+v$$. Entnimmt man einen Knoten, also $$G' = G - v$$, so enthält $$G'$$ gleichzeitig keine der mit $$v$$ inzidenten Kanten. Die Notation zum Hinzufügen und Entfernen von Kanten ist analog, entfernt man jedoch die letzte zu einem bestimmten Knoten inzidente Kante, so bleibt dieser trotzdem Teil des Graphen. Man nennt solche Knoten isoliert.
Existiert zu einem Graphen $$H = (V_H, E_H)$$ ein Graph $$H' = (V_{H'}, E_{H'})$$, so dass $$V_{H'} \subseteq V_H$$ und $$E_{H'} = \{e\in E_H \text{ : } e \cap V_{H'} = e \}$$ gelten, dann nennt man $$H'$$ den durch $$V_{H'}$$ induzierten Teilgraph von $$H$$. Dafür schreibt man auch $$H' = H[V_{H'}]$$. Allgemeiner bezeichnet man $$H'$$ als Teilgraphen von $$H$$, wenn $$V_{H'} \subseteq V_H$$ und $$E_{H'} \subseteq E_H$$ gilt.
Verständnisaufgaben zu Abschnitt 1
Beweisaufgabe - Kannst du's zeigen?
Die Anzahl der Ecken ungeraden Grades in einem Graphen $$G = (V,E)$$ ist gerade.
Hinweise
Konstruiere die Mengen aller ungeraden und geraden Knoten und summiere deren Knotengrade.
Musterlösung
Wir partitionieren die Knotenmenge $$V$$ in $$V_1 = \{v \in V \text{ : } d_G(v) \text{ gerade}\}$$ und $$V_2 = \{v \in V \text{ : } d_G(v) \text{ ungerade}\}$$, welche respektive die Menge aller Knoten geraden und ungeraden Grades darstellen. Zählt die Knotengrade aller Knoten zusammen, so umfasst diese Zahl jede Kante genau zweimal, nämlich für jeden inzidenten Knoten: $$\sum\limits_{v\in V} d_G(v) = 2|E|$$. Es folgt also $$\sum\limits_{v\in V_1} d_G(v) + \sum\limits_{v\in V_2} d_G(v) = 2|E|$$. Der erste Summand muss gerade sein, weil er Summe gerader Knotengrade darstellt. Da $$2|E|$$ ebenfalls gerade ist folgt, dass der zweite Summand auch gerade ist. Da eine Summe ungerader Zahlen nur bei einer geraden Anzahl von Sumanden gerade ist, folgt die Aussage. $$\blacksquare$$
2. Pfade und Kreise
Wähle einen Kreis/Pfad, um ihn im obigen Graphen $$I$$ hervorzuheben.
Ein Weg oder auch Pfad von $$v_1$$ nach $$v_k$$ bezeichnet einen nicht-leeren Graph $$P^k=(V_P,E_P)$$ mit $$V_P = \{v_1,v_2,...,v_k\}$$ und $$E_P=\{\{v_1,v_2\},\{v_2,v_3\},...,\{v_{k-1},v_k\}\}$$. Abkürzend bezeichnet man so einen Kantenzug $$P=v_1v_2...v_k$$. Ausgehend von dieser Definiton nennt man $$P^k$$ einen A-B-Weg genau dann, wenn $$V_P\cap A = \{v_1\}$$ und $$V_P\cap B = \{v_k\}$$ gilt. Analog dazu ist ein a-b-Weg ein A-B-Weg mit $$A=\{a\}$$ und $$B=\{b\}$$.
Der Abstand zweier Knoten $$v_1$$ und $$v_2$$ in $$G$$ bzw. $$d_G(v_1,v_2)$$ ist definiert als die geringste Länge eines $$v_1$$-$$v_2$$-Weges. Den größtmöglichen Abstand zweier Knoten nennt man den Durchmesser von G, oder $$diam(G)$$. Außerdem nennt man einen Knoten $$v$$ zentral, wenn sein Abstand zum entferntesten Knoten minimal ist.
Als Kreis $$C^k$$ bezeichnet man formal $$C^k = P^{k-1} + \{v_{k-1}, v_1\}$$, wobei der Weg $$P^k$$ gleichzeitig als Knotenfolge $$v_1,...,v_{k-1}$$ und auch als Graph $$P^{k-1}=(\{v_1,v_2,...,v_{k-1}\}, \{\{v_1,v_2\},...,\{v_{k-2},v_{k-1}\}\})$$ betrachtet werden kann. Erweitert man diesen um die Kante $$\{v_{k-1}, v_1\}$$ entsteht ein geschlossener Weg der Länge $$k > 2$$, eben ein Kreis. Enthält ein Graph keinen Kreis, so nennt man diesen kreisfrei.
Erfüllt ein Weg die besondere Eigenschaft alle Knoten des zugehörigen Graphen genau einmal zu enthalten, so nennt man ihn einen Hamiltonweg. Ist der Weg zusätzlich geschlossen, existiert also eine Kante zwischen Anfangs- und Endknoten, dann ist der entsprechende Hamiltonweg gleichzeitig ein Hamiltonkreis. Transformiert man diese Überlegungen auf unser anfängliches Problem, dem Haus vom Nikolaus, dann sucht man einen Weg der nicht alle Knoten, sondern alle Kanten des Graphen $$N$$ genau einmal besucht - einen Eulerweg. Analog zum Hamilton- ist der Eulerkreis definiert.
Verständnisaufgaben zu Abschnitt 2
Algorithmusaufgabe
Entwickle einen Algorithmus, der für einen gegebenen Graphen $$G$$ und zwei verschiedene Knoten a und b entscheidet, ob ein a-b-Weg in $$G$$ existiert. Beweise zudem die Korrektheit deines Algorithmus und gebe die Laufzeit in der O-Notation an. Die Datenstruktur des Graphen kannst du dir frei überlegen (siehe z.B Adjazenzliste, Adjazenzmatrix).
Hinweise
Traversiere den Graphen vollständig und merke dir, welche Knoten du bereits besucht hast. Nutze zum Traversieren einen Stack oder eine Queue.
Musterlösung
Ich nehme an der Algorithmus bekommt den Graphen als Knotenarray nodes übergeben, welche jeweils die Methode neighbours() implementieren um alle Nachbarknoten zu ermitteln, und die Instanzvariable visited vom Typ Boolean, die im Initialzustand false ist und angibt, ob ich den jeweiligen Knoten bereits besucht habe.
// Stapel initialisieren und Anfangsknoten drauflegen
Stack s = new Stack();
s.push(a);
a.visited = true;
while !s.isEmpty() {
Node v = nodes.pop();
// Durchlaufe alle noch nicht besuchten Nachbarn von v
for Node n in v.neighbours() {
if n.visited == false {
n.visited = true;
s.push(n);
// Ist der Knoten der Zielknoten, so existiert ein Pfad
if n == b { return true; }
}
}
}
// Alle erreichbaren Knoten wurden durchlaufen ohne 'b' zu finden.
return false;
Korrektheit des Algorithmus
Dass der Zielknoten b genau dann auf dem Stack liegt, wenn er von a aus erreichbar ist, zeige ich in zwei Richtungen. $$(\rightarrow )$$ Ich nehme an der Knoten b liegt auf dem Stack s. Da gefordert ist, dass Ziel- und Anfangsknoten unterschiedlich sind, muss er also in der for-Schleife auf den Stack gelegt worden sein, die über alle unbesuchten Nachbarn eines anderen Knotens $$v$$ iteriert. Da für $$v$$ das gleiche Argument gilt, existiert eine Kette aus Nachbarn bis zum Startknoten a, der EIngabegraph enthält also ein a-b-Weg. $$(\leftarrow )$$ Aus der Annahme, dass ein a-b-Weg existiert folgt, dass es eine Kette von Nachbarn existiert, über die b von a aus erreichbar ist. Da Knoten bloß als besucht markiert werden, wenn sie bereits einmal auf dem Stack waren, muss also jeder dieser Nachbarn der Kette einmal auf dem Stack gelegen haben. Dies gilt auch für den direkten Nachbarn von b (wovon er mindestens einen haben muss, weil ein Weg zu ihm existiert), weswegen folgt, dass auch b einmal auf dem Stack liegt.
Direkt nachdem der Zielknoten auf den Stack gelegt wurde, wird festgestellt, dass er der gesuchte Knoten ist und ein Weg existiert.
Terminierung des Algorithmus
Die einzige Stelle, an der der Algorithmus in eine Endlosschleife fallen könnte, ist in der while-Schleife, die solange läuft bis der Stack leer ist. Jeder Knoten des Eingabegraphen liegt höchstens einmal auf dem Stack, weil er beim drauflegen gleichzeitig als besucht markiert wird und Knoten, die als besucht markiert wurden später nicht mehr betrachtet werden. Da unser Eingabegraph zusätzlich logischerweise endlich ist folgt, dass die Schleife bloß endlich viele Durchläufe macht.
Laufzeit des Algorithmus
Im worst case sind alle Knoten des Graphen zusammenhängend und der Zielknoten wird erst erreicht, wenn bereis alle anderen Knoten auf dem Stack waren. Da bist zu diesem Punkt für jeden Knoten des Graphen alle Nachbarn durchlaufen wurden, egal ob sie bereits besucht wurden oder nicht, entspricht die Laufzeit pro Knoten $$v$$ genau $$\mathcal O(d_G(v))$$. Weil jeder Knoten des Graphen genau einmal auf dem Stack landet ergibt sich folgende Gesamtlaufzeit von $$\mathcal O(n+2m) = \mathcal O(n+m)$$.
3. Zusammenhang
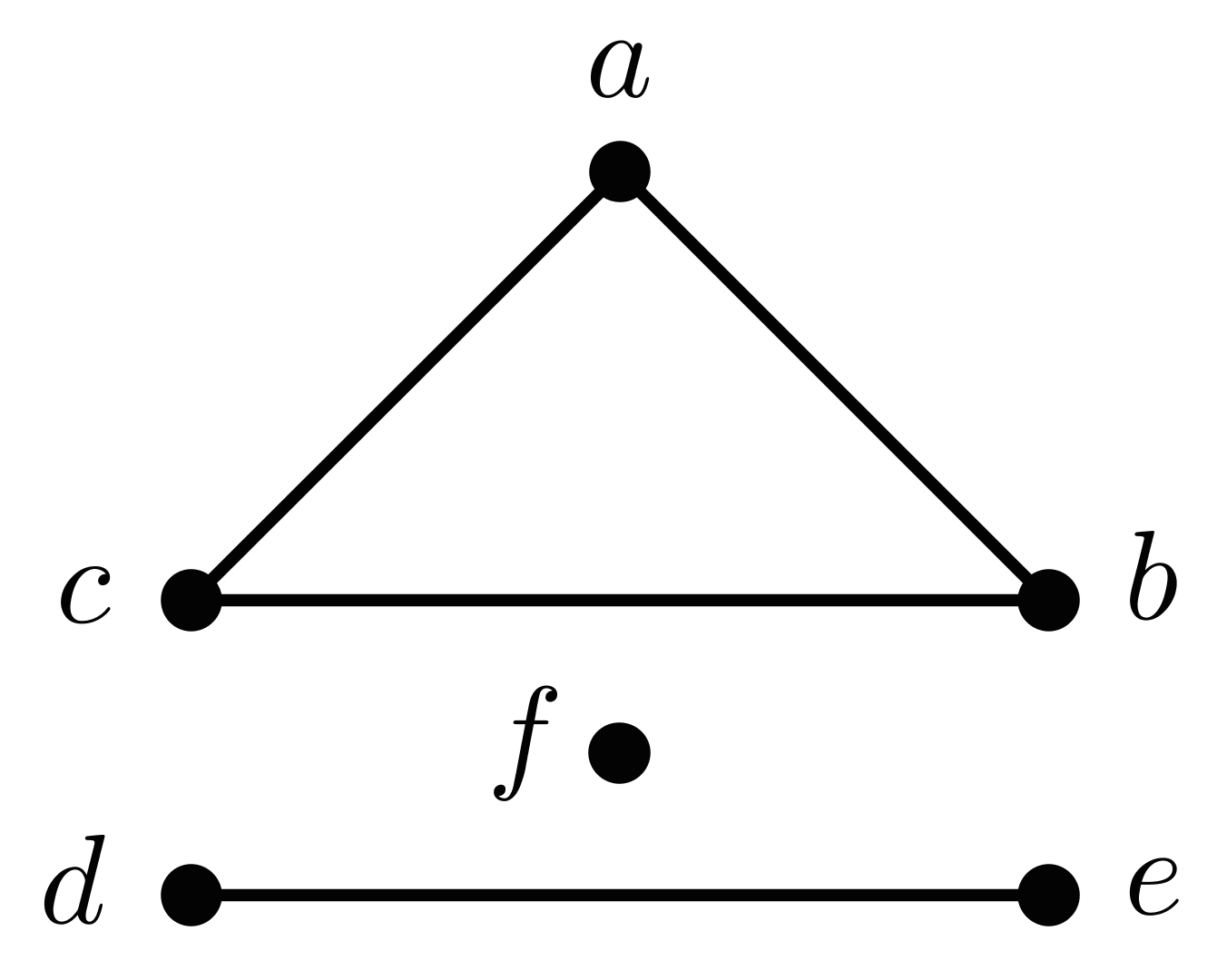
Der Graph $$Z$$ besitzt drei Komponenten: $$Z[\{a,b,c\}]$$, $$Z[\{d,e\}]$$ und $$Z[\{f\}]$$
Eine wichtige Eigenschaft von Graphen ist der Zusammenhang. Man nennt einen nicht-leeren Graphen zusammenhängend, wenn für alle Knoten paarweise ein a-b-Weg existiert. Einen maximal zusammenhängenden Teilgraphen bezeichnet man als Komponente des jeweiligen Graphen. Ein zusammenhängender Graph, wie z.B. der Nikolaus-Graph $$N$$, besitzt genau eine Komponente.
Kann man einem Graphen $$G$$ beliebig $$(k-1)$$-viele Knoten entnehmen, so dass dieser trotzdem zusammenhängend bleibt, so nennt man ihn k-zusammenhängend. Jeder $$k$$-zusammenhängende Graph ist also gleichzeitig $$(k-1)$$-, $$(k-2)$$-, ... und $$0$$-zusammenhängend. Der Zusammenhang $$\kappa(G)$$ steht für das größte solcher $$k$$ für das $$G$$ $$k$$-zusammenhängend ist. Analog dazu ist der Kantenzusammenhang $$\lambda(G)$$ und die Eigenschaft eines Graphen l-kantenzusammenhängend zu sein definiert.
Verständnisaufgaben zu Abschnitt 3
Beweisaufgabe - Kannst du's zeigen?
Ist ein Graph $$G = (V,E)$$ zusammenhängend, so existiert für jedes $$k<n$$ eine Aufzählung seiner Knoten $$(v_1, ..., v_k)$$, so dass $$G[\{v_1,...v_k\}]$$ zusammenhängend ist.
Hinweise
Wähle ein beliebiges $$v_1$$ und versuche nun mit einer bestimmten Reihenfolge über die Knoten zu traversieren (vgl. Algorithmusaufgabe, Abschnitt 2). Du kannst auch einen Algorithmus entwerfen, der das Problem löst und diesen beweisen (Terminierung, Korrektheit).
Musterlösung
Ich werde die Aussage zeigen, indem ich einen Algorithmus angebe, der für einen zusammenhängenden Graphen als Eingabe die gesuchte Aufzählung liefert. Dann zeige ich dessen Korrektheit und Terminierung. Der Eingabegraph G ist eine Menge aller Knoten, die jeweils über die Instanzmethode neighbours() die Menge aller adjazenten Knoten liefert.
// Geordnete Liste initialisieren und beliebigen Startknoten drauflegen
List l = new List();
l.append(G[0]);
while |l| < |G| {
// Menge aller zu l[0],...,l[|l|-1] adjazenten Knoten ohne l
Set newNeighbours = new Set();
for Node n in l {
newNeighbours += (n.neighbours() - l);
}
l.append(newNeighbours[0])
}
return l;
Korrektheit
Für meinen Beweis wähle ich die geforderte Eigenschaft der Aufzählung als Schleifeninvariante für die äußere while-Schleife, nämlich $$G[l] \text{ zusammenhängend}$$. Weil ich in jedem Schleifendurchlauf genau einen Knoten hinzufüge, treffe ich damit jedes $$k \leq n$$. Zur Initialisierung, also vor dem ersten Schleifendurchlauf, trifft die Invariante zu, da ein Graph mit nur einem Knoten immer zusammenhängend ist. Angenommen die Aussage stimmt im $$n$$-ten Durchlauf. Ich zeige nun, dass daraus folgt, dass die Aussage im $$(n+1)$$-ten Durchlauf auch stimmt: Nach Ende der inneren for-Schleife ist jeder Knoten $$v_i$$ der Menge newNeighbours mit mindestens einem Knoten aus l adjazent, weil (wegen Annahme) der induzierte Teilgraph $$G[l]$$ zusammenhängend ist, muss deswegen auch $$G[l+v_0]$$ zusammenhängend sein.
Terminierung
Da der Eingabegraph zusammenhängend ist, wächst l solange um genau einen Knoten pro Iteration, bis alle Knoten aus G enthalten sind. Das sieht man leicht an der Kontraposition. $$\blacksquare$$
Algorithmusaufgabe
Entwickle zwei Algorithmen, die für einen gegebenen Graphen $$G$$ entscheiden, ob dieser zusammenhängend ist. Nutze für die erste Variante den Algorithmus der Aufgabe von Abschnitt 2, nennen wir ihn z.B. existiertWeg(a,b,Graph), der true liefert wenn ein a-b-Weg im Eingabegraph existiert, sonst false. Die zweite Variante soll den Algorithmus der Musterlösung aus Abschnitt 2 modifizieren.
Gebe für beide Varianten eine Laufzeit in O-Notation an. Korrektheits- und Terminierungs-Beweise brauchst du diesesmal nicht machen.
Hinweise
Für Variante 1: Implementiere die exakte Definition von Zusammenhang.
Für Variante 2: Nutze die visited-Instanzvariable eines jeden Knotens. Wähle einen beliebigen Startpunkt für die Traversierung.
Musterlösung
Variante 1
Der Eingabegraph G ist genau dann zusammenhängend, wenn für alle seine Knoten $$a,b$$ ein $$a$$-$$b$$-Weg existiert. Man durchläuft also alle $$\binom{n}{2}$$ Knotenpaare und ruft existiertWeg(a,b,Graph) auf, was jeweils $$\mathcal O(n+m)$$ dauert.
forall pairs of Nodes (a, b) in G {
if !existiertWeg(a,b,G) { return false; }
}
return true;
Daraus ergibt sich eine ernüchternde Gesamtlaufzeit von $$\mathcal O(n*(n-1)/2*(n+m)) = \mathcal O(n^3+mn^2)$$.
Variante 2
Wir nehmen den Algorithmus aus der Aufgabe von Abschnitt 2 und entfernen die Überprüfung auf einen gewissen Zielknoten, sondern lassen die Tiefensuche solange arbeiten, bis sie alle erreichbaren Knoten besucht hat. Existiert dann trotzdem noch ein unbesuchter Knoten in G, so muss dieser in einer anderen Zusammenhangskomponenten liegen.
// Stapel initialisieren und beliebigen Anfangsknoten drauflegen
Stack s = new Stack();
s.push(G[0]);
a.visited = true;
while !s.isEmpty() {
Node v = nodes.pop();
// Lege alle noch nicht besuchten Nachbarn auf den Stapel
for Node n in v.neighbours() {
if n.visited == false {
n.visited = true;
s.push(n);
}
}
}
// Sollte ein Knoten noch nicht besucht sein, dann liegt er in einer anderen Komponente
for Node n in G {
if !n.visited { return false; }
}
return true;
Die Laufzeit ist der aus Variante 1 deutlich überlegen, sie beträgt trotz der zusätzlichen Überprüfung des Besuchs aller Knoten noch $$\mathcal O(n+m)$$.
4. Spezialformen: Bäume und partite Graphen
In vielen Anwendungsbereichen erfüllen Graphen nachdem sie modelliert wurden spezielle Eigenschaften oder man sucht Teilgraphen die spezielle Eigenschaften erfüllen. Mindestens einen solcher Spezialfälle haben wir bereits kennengelernt, nämlich den zusammenhängenden Graphen, in dem jeder Knoten von jedem anderen aus erreichbar ist. Diese Eigenschaft ist in der Routenplanung besonders wünschenswert und kann global (siehe Google-Maps) zum Beispiel durch die Integration von Fähren- und Luftrouten zwischen den Kontinenten und Inselgruppen der Welt sichergestellt werden. Im Folgenden führe ich zwei andere praxisrelevante Sonderformen ein: Bäume und partite Graphen.
Der maximal-kreisfreie Graph $$B$$, ein Baum.
Bäume
Einen Graphen, der gleichzeitig zusammenhängend und kreisfrei ist, bezeichnet man als Baum. Allgemeiner nennt man einen Graphen, der aus mindestens einer kreisfreien Komponente besteht, einen Wald. Alle Knoten eines Baumes mit nur einer inzidenten Kante nennt man Blätter. Satz 0.5.1 aus Diestels Graphentheorie offenbart uns die wichtigsten Äquivalenzen eines Baums:
Die folgenden Aussagen sind äquivalent für einen Graphen $$G$$:
$$G$$ ist ein Baum
Für je zwei Knoten $$a,b$$ enthält $$G$$ genau einen $$a$$-$$b$$-Weg.
$$G$$ ist minimal zusammenhängend.
$$G$$ ist maximal kreisfrei.
Viele Graph-Algorithmen (z.B. Wegfindung oder Ermittlung des zentralen Knotens) lassen sich auf Bäumen noch effizienter implementieren. Oft ist Ziel eines Problems auch, einen Teilgraphen eines (nicht-kreisfreien) Eingabegraphen $$G$$ zu finden, so dass dieser die Eigenschaften eines Baumes erfüllt und gleichzeitig alle Knoten von $$G$$ enthält - Man nennt diesen speziellen Teilgraphen Spannbaum.
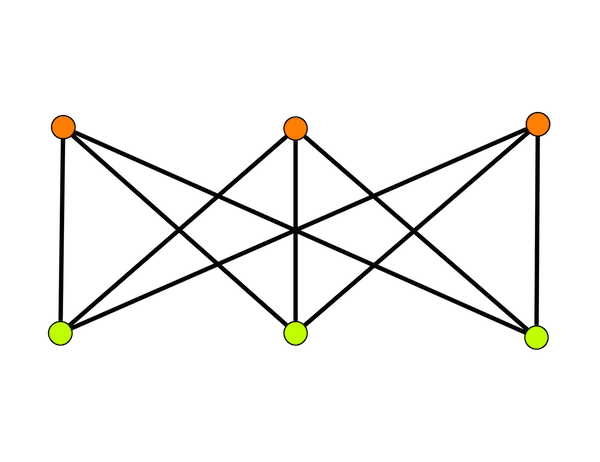
Verschiedene Darstellungen partiter Graphen. Die einzelnen Partitionen sind farblich hervorgehoben.
Partite Graphen
Bildet man einen Graphen $$R$$ aus einer Menge von Arbeitern (Knoten), Aufgaben (Knoten) und Aufgabenpräferenzen der Arbeiter (Kanten), dann wird deutlich dass $$R$$ in zwei Partitionen zerfällt, deren Knoten untereinander keine Kanten teilen: Die der Aufgaben und der Arbeiter. Graphen die vollständig in $$k$$ solcher Partitionen zerfallen, nennt man $$k$$-partit. Unser Graph $$R$$ ist also 2-partit oder bipartit. Vollständige $$k$$-partite Graphen bezeichnet man auch mit $$K_{n_1,...,n_k}$$, wobei $$n_i$$ die Anzahl der Knoten der $$i$$-ten Partiton angibt.
Gesucht ist nun eine maximale Menge knotendisjunkter Kanten, also eine optimale Aufgabenzuordnung. Diese Problemstellung hat in vielen Gebieten große Relevanz, man bezeichnet sie als Matching oder Paarung.
Schon die bipartiten Graphen eröffnen ein weites Forschungsfeld, zum Beispiel geht es um die algorithmischen Fragestellungen: Wie kann ein solches Matching gefunden werden? Existiert ein perfektes Matching? Ist ein gegebener Graph bipartit?
Verständnisaufgaben zu Abschnitt 4
Beweisaufgabe - Kannst du's zeigen?
Beweise die folgenden Sätze:
Jeder Baum $$T = (V,E)$$ mit $$|V| \geq 2$$ enthält mindestens zwei Blätter.
Jeder Baum $$P$$ hat mindestens so viele Blätter wie $$\Delta(P)$$.
Hinweise
Wähle für beide Sätze entweder eine Startkante oder einen Starknoten, traversiere den Graphen und nutze eine Baum-Eigenschaft.
Musterlösung
Sei $$\{v,u\} \in E$$ eine beliebige Kante. Nun traversieren wir so lange in Richtung von $$v$$ und nach $$u$$, bis wir bei einem Blatt ankommen. Dabei ist es egal, wo lang wir genau gehen, da $$T$$ keine Kreise enthält und wir eine Kante bzw. einen Knoten deswegen nur höchstens einmal besuchen. $$T$$ ist außerdem endlich, weshalb wir irgendwann in beiden Richtungen in einer Sackgasse, als einem Blatt, terminieren. $$\blacksquare$$
In $$P$$ existiert mindestens ein Knoten $$v$$ mit $$d_G(v)=\Delta(P)$$. Beginnend bei $$v$$ traversieren wir den Graphen wie in i. in alle $$\Delta(P)$$ Richtungen. $$\blacksquare$$
5. Erweiterungen: Gerichtete Graphen und Kantengewichte
Das kennengelernte Modell eines Graphen scheint zwar bereits äußerst vielseitig, stößt bei vielen Problem-Modellierung jedoch schnell an seine Grenzen. Für die meisten Praxis-Anwendungen ist es nötig die Kanten eines Graphen zu richten, also nur in eine Richtung begehbar zu machen und um einen Weg dem anderen gegenüber zu präferieren muss neben der Anzahl der Kanten auch eine spezielle Kantenwichtung verfügbar sein. Beide Modelle stelle ich nun kurz als Ausblick vor.
Gerichtete Graphen
Der gerichtete, kreisfreie Graph (DAG) $$D$$.
Betrachtet man zum Beispiel zwei Orte $$a, b$$ (die in einem Graphen als Knoten dargestellt sind) welche durch genau eine Einbahnstraße verbunden sind, dann wäre es nicht sinnvoll diese Kante als ungerichtete Menge $$\{a,b\}$$ zu abstrahieren. Eine gerichtete Kante hingegen ist als geordnetes Tupel $$(a,b)$$ definiert. Graphen können entweder nur ungerichtete oder gerichtete Kanten enthalten, man nennt sie dann respektive ungerichtet oder gerichtet.
Alle der besprochenen Termini lassen sich intuitiv für gerichtete Graphen formulieren, zum Beispiel ist kommt jedem Knoten $$v$$ nun ein gesonderter Ausgangs- und Eingangsgrad für die Anzahl ausgehender Kanten $$d^+_G(v)$$ bzw. die der eingehenden $$d^-_G(v)$$ zu.
Ein gerichteter Weg $$P^k=v_1v_2...v_k$$ ist nichts anderes als ein nicht-leerer Graph mit Knotenmenge $$\{v_1,v_2,...,v_k\}$$ und Kantenmenge $$\{(v_1,v_2),...,(v_{k-1},v_k)\}$$. Ein gerichteter Kreis ist also $$C^k = P^{k-1} + (v_{k-1}, v_0)$$.
Ein gerichteter, kreisfreier Graph hat den Spezialbegriff DAG. In jedem DAG existiert mindestens ein Knoten $$q$$ mit $$d^-_G(q)=0$$, die Quelle - Und mindestens ein Knoten $$s$$ mit $$d^+_G(s)=0$$, die Senke. Jeder DAG verfügt über mindestens eine topologische Sortierung, welche eine Reihenfolge $$(v_1, ..., v_n)$$ aller Knoten des Graphen darstellt, die die Eigenschaft erfüllt, dass nur Kanten der Form $$(v_i, v_j)$$ mit $$j>i$$ existieren.
Gewichtete Graphen
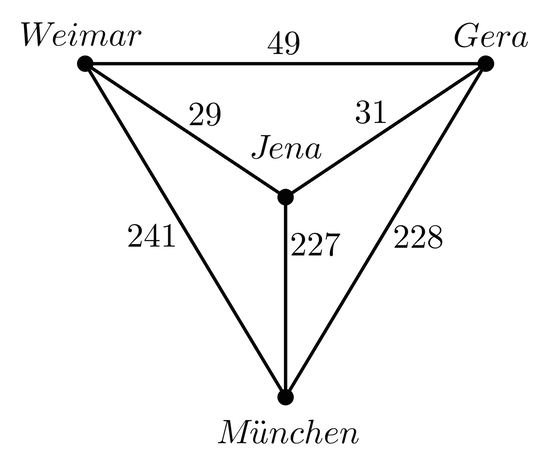
Approximierte Fahrzeiten in Minuten modelliert als vollständiger, gewichteter Graph $$W$$.
Nehmen wir wieder zwei Orte $$a,b$$, die nun über eine direkte Straße von 1km und einer direkten Umgehungsstraße von 3km verbunden sind. Es ergibt sich intuitiv die Fragestellung, nicht nur einen Weg von $$a$$ nach $$b$$ zu finden, sondern eben den kürzesten Weg. Unser herkömmliches Graph-Modell erweitern wir dazu um eine Gewichtsfunktion $$\omega: E \rightarrow \mathbb{R}$$, so dass wir einen gewichteten Graphen als $$G = (V,E,\omega)$$ beschreiben. Die Wichtungen sind natürlich nicht nur auf Weglängen beschränkt, sondern können jede messbare Entität darstellen.
Die zusätzliche Wichtung eröffnet vielen bereits besprochenen Problemfeldern eine neue Optimierungs-Dimension. Man sucht nun zum Beispiel minimale/maximale Spannbäume und den kürzesten $$a$$-$$b$$- oder Hamilton-Weg. Kombiniert man einen gerichteten, kreisfreien Graphen (DAG) mit zusätzlichen Kantengewichten, dann handelt es sich um ein Netzwerk, welches man auf die maximal-übertragbare Kapazität zwischen einer Quelle und einer Senke untersuchen kann.
Verständnisaufgaben zu Abschnitt 5
Beweisaufgabe - Kannst du's zeigen?
Beweise die oben postulierte Aussage, dass jeder gerichtete, kreisfreie Graph $$G = (V,E)$$ mindestens eine Quelle $$q$$ mit $$d_G^-(q) = 0$$ enthält. Schlussfolgere daraus, dass auch eine Senke $$s$$ vorhanden sein muss.
Hinweise
Nehme an, jeder Knoten besitzt mindestens eine eingehende Kante und führe das zum Widerspruch.
Musterlösung
Ich nehme an für jeden Knoten $$v_i$$ gilt $$d_G^-(v_i) \geq 1$$. Dann wähle ich ein beliebiges $$v_i$$ und traversiere rückwärts zum Knoten $$v_{i-1}$$ für den $$(v_{i-1},v_i)$$ in $$E$$ liegt. Da jeder Knoten per Annahme mindestens einen solchen adjazenten Knoten besitzt und $$G$$ aber azyklisch und endlich ist, muss irgendwann ein letzter Knoten $$v_0$$ mit $$d_G^-(v_0) = 0$$ erreicht sein. Damit ist ein Widerspruch erzeugt, $$v_0$$ ist die Quelle. $$\blacksquare$$
Die Existenz einer Senke lässt sich mit analoger Argumentation für den Ausgangsgrad zeigen.
Ende des Lehrinhalts, unten findest du weiterführendes Material
I. Quellen und weiterführendes Material
Neben zahlreichen Wikipedia-Artikeln aus dem Themengebiet der Graphentheorie existieren weitere Ressourcen, die ich zum tiefgehenderen Studium besonders empfehle:
Zusammenfassung aller wichtigen Termini von mir akkumuliert aus dem Diestel und Wikipedia von den hier behandelten Grundbegriffen bis zu Minoren, Cliquen, DAGs, Färbungen und planaren Graphen.
Ausführliches Einführungswerk geeignet für Neulinge wegen einleitender Erklärung der Aussagenlogik und wichtiger Beweiskonzepte. Erstreckt sich bishin zu wichtigen graphtheoretischen Algorithmen.