Algorithms
Metanome Tool and Profiling Algorithms
The Metanome profiling tool is a framework for various profiling algorithms. It handles both algorithms and datasets as external resources, which is why there are no profiling algorithms contained in tool itself. Having algorithms as external resources is a design decision that allows researches to contribute profiling functionality without changing the tool itself. This makes Metanome on open profiling platform for both algorithm engineers and data scientists. The following image depicts the architecture of the profiling tool:
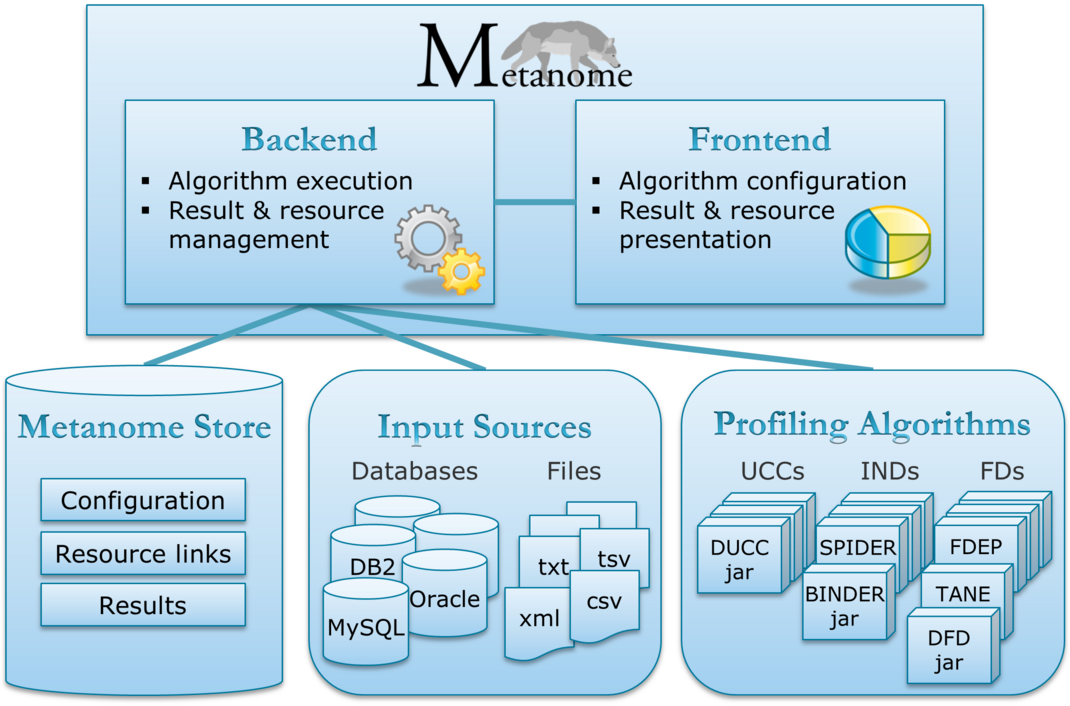
Metanome Tool
Metanome Datasets
To load a dataset into the Metanome tool, it must be placed into the folder /WEB-INF/classes/inputData. It will then appear in the frontend in the import list. The datasets need to be relational and in some kind of csv or tsv format. The separator and quote characters can be defined in the frontend when importing the individual datasets. Alternatively to file-imports, one can specify a database connection in the frontend.
We provide some test datasets on our repeatability page.
Metanome Algorithms
In the context of the Metanome data profiling project, we developed and re-implemented the following profiling algorithms. To run a profiling algorithm, place the according jar-file into the folder /WEB-INF/classes/algorithms and register it in the Metanome frontend. If you want to write your own profiling algorithm for the Metanome tool, we recommend this Skeleton Project to start your development.
The source code for these algorithms is also available on GitHub.
Unique Column Combination (Key Discovery)
Inclusion Dependency (Foreign-Key Discovery) repeatability page
- BINDER (v0.0.2, v1.0, v1.1, v1.2)
- BINDER Database (v0.0.2, v1.0, v1.1, v1.2)
- SPIDER (v0.0.2, v1.0, v1.1, v1.2)
- SPIDER Database (v0.0.2, v1.0, v1.1, v1.2)
- MANY (v0.0.2, v1.0, v1.1, v1.2)
- FAIDA (v0.0.2, v1.0, v1.1, v1.2) (approximate)
Functional Dependencies (Normalization) repeatability page
- HyFD (v1.1, v1.2)
- DFD (v0.0.2, v1.0, v1.1, v1.2)
- Tane (v0.0.2, v1.0, v1.1, v1.2)
- Fun (v0.0.2, v1.0, v1.1, v1.2)
- fdep (v0.0.2, v1.0, v1.1, v1.2)
- FastFDs (v0.0.2, v1.0, v1.1, v1.2)
- FdMine (v0.0.2, v1.0, v1.1, v1.2)
- DepMiner (v0.0.2, v1.0, v1.1, v1.2)
- AIDFD (v0.0.2, v1.0, v1.1, v1.2) (approximate)
- CFDFinder (v1.1, v1.2) (conditional)
Matching Dependencies (Data Cleaning) repeatability page
Multivalued Dependencies (Normalization)
Order Dependencies (Data Ordering) repeatability page
Denial Constraints (Data Cleaning) repeatability page
Complement Dependencies(Data Cleaning)
- Cody (v1.2)
Basic Statistics (Data Exploration)
Cardinality Estimation (Zeroth-frequency moment of dataset) repeatability page
- FM (v1.1, v1.2)
- PCSA (v1.1, v1.2)
- LC (v1.1, v1.2)
- AMS (v1.1, v1.2)
- BJKST (v1.1, v1.2)
- LogLog (v1.1, v1.2)
- SuperLogLog (v1.1, v1.2)
- MinCount (v1.1, v1.2)
- AKMV (v1.1, v1.2)
- HyperLogLog (v1.1, v1.2)
- Bloom filter (v1.1, v1.2)
- HyperLogLog++ (v1.1, v1.2)
Schema Normalization
Further Profiling Algorithms
The following list points to data profiling algorithms that have been developed also in the context of the Metanome project, but that do not support the Metanome algorithm interface:
Inclusion Dependencies
- https://github.com/srfc/raida (distributed)
- https://github.com/alpreu/spin (distributed on streaming data)
Functional Dependencies
- https://github.com/HPI-Information-Systems/dynfd (on dynamic data)
Bidirectional Order Dependencies
- DISTOD (Sources and Releases on Github) (distributed, discovers ODs in set-based form) repeatability page
Key and Foreign Key Discovery with HoPF