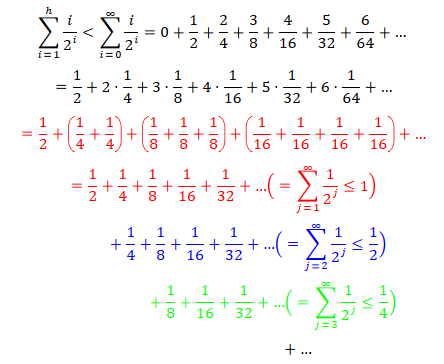Die Operationen der Queue sind jeweils konstant und wir können leicht mit einem Zeiger durch das Array laufen, um die entsprechenden Schlüsselwerte auszulesen.
Nun analysieren wir, was in der for-Schleife passiert. Wir wollen eine obere Schranke zeigen und nehmen deshalb an, dass wir für maximal viele Knoten MinVersickere aufrufen und jeder Aufruf so teuer wie möglich ist. Wir haben uns bereits überlegt, dass die Kosten von MinVersickere für einen Knoten mit Höhe \(k\) in \(\Theta(k)\) liegen, das heißt, die Kosten sind höchstens \(c\cdot k\) für eine Konstante \(c\). Für unsere obere Schranke müssen wir uns somit nur noch überlegen, wie viele Knoten wir versickern und welche Höhe sie jeweils haben, und dann addieren wir alle Kosten einfach auf.
Bei BuildMinHeap beginnen wir im vorletzten Level des Binärbaums und im schlimmsten Fall sind dort alle Knoten auch Elternknoten und jeder Elternknoten hat genau zwei Kinder. Wir nehmen also an, dass auch das letzte Level vollständig gefüllt ist. Mit Hilfe von Lemma 1 gilt deshalb \(n = \sum_{i=0}^h 2^i = 2^{h+1}-1\), wobei \(h\) die Höhe der Wurzel ist. Außerdem gilt, dass das vorletzte Level genau \(2^{h-1}\) Knoten enthält, das vorvorletzte \(2^{h-2}\) usw. bis zum \(0\)-ten Level, das nur die Wurzel und somit \(2^0\) Knoten enthält.
Die Knoten im \(0\)-ten Level, d. h. nur die Wurzel, haben Höhe \(h\) und somit kostet das Versickern der Wurzel höchstens \(c\cdot h\). Die Knoten im ersten Level haben Höhe \(h-1\) und somit kostet das Versickern pro Knoten in diesem Level höchstens \(c \cdot (h-1)\). Allgemein gilt, dass Knoten im Level \(i\), für \(0\leq i \leq h-1\), eine Höhe von genau \(h-i\) haben und somit das Versickern pro Knoten in Level \(i\) höchstens \(c \cdot (h-i)\) kostet.
Wir haben uns bereits überlegt, dass es höchstens \(\frac{n}{2^{i}}\) viele Knoten mit Höhe \(i\) gibt.
Für Anzahl der Knoten mit Höhe \(h\) gilt folgendes: Sei \(n(h)\) die Anzahl der Knoten mit Höhe \(h\). Aus Lemma 1 folgt, dass \[n(h) \leq \frac{n}{2^h}\ .\]
Seien \(C(n)\) die Kosten von BuildMinHeap auf einem Array mit \(n\) Elementen, wobei \(2^{h}-1 < n \leq 2^{h+1}-1\). Dann gilt:
\[C(n) \leq \sum_{i=0}^{h-1} 2^{i} \cdot c \cdot (h-i) = c \cdot \sum_{i=0}^{h-1} 2^{i} \cdot (h-i) \leq c \cdot \sum_{i=0}^{h-1} \frac{n}{2^{h-i}}\cdot (h-i)\] \[ = cn \cdot \sum_{i=0}^{h-1} \frac{h-i}{2^{h-i}} = cn \cdot \left(\frac{h}{2^h} + \frac{h-1}{2^{h-1}} + … + \frac{h-(h-1)}{2^{h-(h-1)}} \right) = cn \cdot \sum_{i = 1}^{h} \frac{i}{2^i}\ . \]
Es gilt