Differentially-Private Federated Learning with Non-IID Data For Surgical Risk Prediction. Pfitzner, Bjarne; Maurer, Max M.; Winter, Axel; Riepe, Christoph; Sauer, Igor M.; van de Water, Robin; Arnrich, Bert in 2024 IEEE First International Conference on Artificial Intelligence for Medicine, Health and Care (AIMHC) (2024). 120–129.
Federated learning (FL) has emerged as a promising solution to deal with the privacy concerns which often limit access to data for training machine learning (ML) models. It encompasses the exchange of model parameters between data owners and a central model aggregation instance without the need to share sensitive data directly. Although FL does not require sharing sensitive information, it may not guarantee complete privacy, as model parameters can potentially reveal sensitive details about the underlying training data. To enhance privacy, FL approaches can additionally integrate differential privacy (DP), which entails the careful addition of noise to the model. In this paper, we investigate the relationship between FL, DP, and highly non-independent and identically distributed (non-IID) data. We present a specific real-life healthcare applica tion of predicting patient mortality and revision surgery after visceral operations. Our contributions encompass assessing the performance of FL with and without DP in the presence of highly non-IID data, analysing the fairness for individual training participants and investigating the efficacy of personalisation to alleviate the privacy-utility trade-off introduced by DP. Our findings indicate that the addition of DP into FL given non-IID datasets disparately favours participants with larger datasets, while the model has limited utility for those with less data. The addition of a subsequent model fine-tuning step can remedy this disparity and enables all participants to reach a model performance comparable to the centralised training scenario.
Predictive Alarm Prevention by Forecasting Threshold Alarms at the Intensive Care Unit. Chromik, Jonas; Pfitzner, Bjarne; Ihde, Nina; Michaelis, Marius; Schmidt, Denise; Klopfenstein, Sophie Anne Ines; Poncette, Akira-Sebastian; Balzer, Felix; Arnrich, Bert in Biomedical Engineering Systems and Technologies, A. C. A. Roque, D. Gracanin, R. Lorenz, A. Tsanas, N. Bier, A. Fred, H. Gamboa (reds.) (2023). (Vol. 1814) 215–236.
Federated Learning for Activity Recognition: A System Level Perspective. Kalabakov, Stefan; Jovanovski, Borche; Denkovski, Daniel; Rakovic, Valentin; Pfitzner, Bjarne; Konak, Orhan; Arnrich, Bert; Gjoreski, Hristijan in IEEE Access (2023). 11 64442–64457.
The past decade has seen substantial growth in the prevalence and capabilities of wearable devices. For instance, recent human activity recognition (HAR) research has explored using wearable devices in applications such as remote monitoring of patients, detection of gait abnormalities, and cognitive disease identification. However, data collection poses a major challenge in developing HAR systems, especially because of the need to store data at a central location. This raises privacy concerns and makes continuous data collection difficult and expensive due to the high cost of transferring data from a user’s wearable device to a central repository. Considering this, we explore the adoption of federated learning (FL) as a potential solution to address the privacy and cost issues associated with data collection in HAR. More specifically, we investigate the performance and behavioral differences between FL and deep learning (DL) HAR models, under various conditions relevant to real-world deployments. Namely, we explore the differences between the two types of models when (i) using data from different sensor placements, (ii) having access to users with data from heterogeneous sensor placements, (iii) considering bandwidth efficiency, and (iv) dealing with data with incorrect labels. Our results show that FL models suffer from a consistent performance deficit in comparison to their DL counterparts, but achieve these results with much better bandwidth efficiency. Furthermore, we observe that FL models exhibit very similar responses to those of DL models when exposed to data from heterogeneous sensor placements. Finally, we show that the FL models are more robust to data with incorrect labels than their centralized DL counterparts.
Computational Approaches to Alleviate Alarm Fatigue in Intensive Care Medicine: A Systematic Literature Review. Chromik, Jonas; Klopfenstein, Sophie Anne Ines; Pfitzner, Bjarne; Sinno, Zeena-Carola; Arnrich, Bert; Balzer, Felix; Poncette, Akira-Sebastian in Frontiers in Digital Health (2022). 4
Patient monitoring technology has been used to guide therapy and alert staff when a vital sign leaves a predefined range in the intensive care unit (ICU) for decades. However, large amounts of technically false or clinically irrelevant alarms provoke alarm fatigue in staff leading to desensitisation towards critical alarms. With this systematic review, we are following the Preferred Reporting Items for Systematic Reviews (PRISMA) checklist in order to summarise scientific efforts that aimed to develop IT systems to reduce alarm fatigue in ICUs. 69 peer-reviewed publications were included. The majority of publications targeted the avoidance of technically false alarms, while the remainder focused on prediction of patient deterioration or alarm presentation. The investigated alarm types were mostly associated with heart rate or arrhythmia, followed by arterial blood pressure, oxygen saturation, and respiratory rate. Most publications focused on the development of software solutions, some on wearables, smartphones, or headmounted displays for delivering alarms to staff. The most commonly used statistical models were tree-based. In conclusion, we found strong evidence that alarm fatigue can be alleviated by IT-based solutions. However, future efforts should focus more on the avoidance of clinically non-actionable alarms which could be accelerated by improving the data availability.
Extracting Alarm Events from the MIMIC-III Clinical Database. Chromik., Jonas; Pfitzner., Bjarne; Ihde., Nina; Michaelis., Marius; Schmidt., Denise; Klopfenstein., Sophie; Poncette., Akira-Sebastian; Balzer., Felix; Arnrich., Bert (2022). 328–335.
Lack of readily available data on ICU alarm events constitutes a major obstacle to alarm fatigue research. There are ICU databases available that aim to give a holistic picture of everything happening at the respective ICU. However, these databases do not contain data on alarm events. We utilise the vital parameters and alarm thresholds recorded in the MIMIC-III database in order to artificially extract alarm events from this database. Prior to that, we uncover, investigate, and mitigate inconsistencies we found in the data. The results of this work are an approach and an algorithm for cleaning the alarm data available in MIMIC-III and extract concrete alarm events from them. The data set generated by this algorithm is investigated in this work and can be used for further research into the problem of alarm fatigue.
Forecasting Thresholds Alarms in Medical Patient Monitors using Time Series Models. Chromik., Jonas; Pfitzner., Bjarne; Ihde., Nina; Michaelis., Marius; Schmidt., Denise; Klopfenstein., Sophie; Poncette., Akira-Sebastian; Balzer., Felix; Arnrich., Bert (2022). 26–34.
Too many alarms are a persistent problem in today’s intensive care medicine leading to alarm desensitisation and alarm fatigue. This puts patients and staff at risk. We propose a forecasting strategy for threshold alarms in patient monitors in order to replace alarms that are actionable right now with scheduled tasks in an attempt to remove the urgency from the situation. Therefore, we employ both statistical and machine learning mod- els for time series forecasting and apply these models to vital parameter data such as blood pressure, heart rate, and oxygen saturation. The results are promising, although impaired by low and non-constant sampling frequencies of the time series data in use. The combination of a GRU model with medium-resampled data shows the best performance for most types of alarms. However, higher time resolution and constant sampling frequencies are needed in order to meaningfully evaluate our approach.
Defending against Reconstruction Attacks through Differentially Private Federated Learning for Classification of Heterogeneous Chest X-ray Data. Ziegler, Joceline; Pfitzner, Bjarne; Schulz, Heinrich; Saalbach, Axel; Arnrich, Bert in Sensors, (F. Marulli; L. Verde, reds.) (2022). 22(14)
Privacy regulations and the physical distribution of heterogeneous data are often primary concerns for the development of deep learning models in a medical context. This paper evaluates the feasibility of differentially private federated learning for chest X-ray classification as a defense against data privacy attacks. To the best of our knowledge, we are the first to directly compare the impact of differentially private training on two different neural network architectures, DenseNet121 and ResNet50. Extending the federated learning environments previously analyzed in terms of privacy, we simulated a heterogeneous and imbalanced federated setting by distributing images from the public CheXpert and Mendeley chest X-ray datasets unevenly among 36 clients. Both non-private baseline models achieved an area under the receiver operating characteristic curve (AUC) of 0.94 on the binary classification task of detecting the presence of a medical finding. We demonstrate that both model architectures are vulnerable to privacy violation by applying image reconstruction attacks to local model updates from individual clients. The attack was particularly successful during later training stages. To mitigate the risk of a privacy breach, we integrated Rényi differential privacy with a Gaussian noise mechanism into local model training. We evaluate model performance and attack vulnerability for privacy budgets ε∈1,3,6,10. The DenseNet121 achieved the best utility-privacy trade-off with an AUC of 0.94 for ε=6. Model performance deteriorated slightly for individual clients compared to the non-private baseline. The ResNet50 only reached an AUC of 0.76 in the same privacy setting. Its performance was inferior to that of the DenseNet121 for all considered privacy constraints, suggesting that the DenseNet121 architecture is more robust to differentially private training.
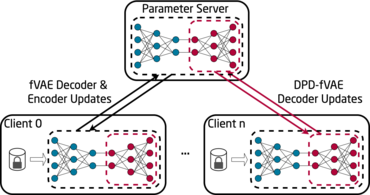
DPD-fVAE: Synthetic Data Generation Using Federated Variational Autoencoders With Differentially-Private Decoder Pfitzner, Bjarne; Arnrich, Bert (2022).
Federated learning (FL) is getting increased attention for processing sensitive, distributed datasets common to domains such as healthcare. Instead of directly training classification models on these datasets, recent works have considered training data generators capable of synthesising a new dataset which is not protected by any privacy restrictions. Thus, the synthetic data can be made available to anyone, which enables further evaluation of machine learning architectures and research questions off-site. As an additional layer of privacy-preservation, differential privacy can be introduced into the training process. We propose DPD-fVAE, a federated Variational Autoencoder with Differentially-Private Decoder, to synthesise a new, labelled dataset for subsequent machine learning tasks. By synchronising only the decoder component with FL, we can reduce the privacy cost per epoch and thus enable better data generators. In our evaluation on MNIST, Fashion-MNIST and CelebA, we show the benefits of DPD-fVAE and report competitive performance to related work in terms of Fréchet Inception Distance and accuracy of classifiers trained on the synthesised dataset.
Perioperative Risk Assessment in Pancreatic Surgery Using Machine Learning. Pfitzner, Bjarne; Chromik, Jonas; Brabender, Rachel; Fischer, Eric; Kromer, Alexander; Winter, Axel; Moosburner, Simon; Sauer, Igor M.; Malinka, Thomas; Pratschke, Johann; Arnrich, Bert; Maurer, Max M. (2021). 2211–2214.
Pancreatic surgery is associated with a high risk for postoperative complications and death of patients. Complications occur in a variable interval after the procedure. Often, a patient has already left the ICU and is not properly monitored anymore when the complication occurs. Risk stratification models can assist in identifying patients at risk in order to keep these patients in ICU for longer. This, in turn, helps to identify complications earlier and increase survival rates. We trained multiple machine learning models on pre-, intra- and short term postoperative data from patients who underwent pancreatic resection at the Department of Surgery, Campus Charité Mitte | Campus Virchow-Klinikum, Charité – Universitätsmedizin Berlin. The presented models achieve an area under the precision-recall curve (AUPRC) of up to 0.51 for predicting patient death and 0.53 for predicting a specific major complication. Overall, we found that a classical logistic regression model performs best for the investigated classification tasks. As more patient data becomes available throughout the perioperative stay, the performance of the risk stratification model improves and should therefore repeatedly be computed.
Implicit Model Specialization through Dag-Based Decentralized Federated Learning. Beilharz, Jossekin; Pfitzner, Bjarne; Schmid, Robert; Geppert, Paul; Arnrich, Bert; Polze, Andreas in Middleware ’21 (2021). 310–322.
Federated learning allows a group of distributed clients to train a common machine learning model on private data. The exchange of model updates is managed either by a central entity or in a decentralized way, e.g. by a blockchain. However, the strong generalization across all clients makes these approaches unsuited for non-independent and identically distributed (non-IID) data.We propose a unified approach to decentralization and personalization in federated learning that is based on a directed acyclic graph (DAG) of model updates. Instead of training a single global model, clients specialize on their local data while using the model updates from other clients dependent on the similarity of their respective data. This specialization implicitly emerges from the DAG-based communication and selection of model updates. Thus, we enable the evolution of specialized models, which focus on a subset of the data and therefore cover non-IID data better than federated learning in a centralized or blockchain-based setup.To the best of our knowledge, the proposed solution is the first to unite personalization and poisoning robustness in fully decentralized federated learning. Our evaluation shows that the specialization of models emerges directly from the DAG-based communication of model updates on three different datasets. Furthermore, we show stable model accuracy and less variance across clients when compared to federated averaging.
Sensor-Based Obsessive-Compulsive Disorder Detection With Personalised Federated Learning. Kirsten, Kristina; Pfitzner, Bjarne; Löper, Lando; Arnrich, Bert (2021). 333–339.
The mental illness Obsessive-Compulsive Disorder (OCD) is characterised by obsessive thoughts and compulsive actions. The latter can occur as repetitive activities to ensure that severe fears do not come true. A diagnosis of the disease is usually very late due to a lack of knowledge and shame of the patient. Nevertheless, early detection can significantly increase the success of therapy. With the development of new wearable sensors, it is possible to recognise human activities. Accordingly, wearables can also be used to identify recurring activities that indicate an OCD. Through this form of an automatic detection system, a diagnosis can be made earlier and thus therapy can be started sooner. Since compulsive behaviour is very individual and varies from patient to patient, this paper deals with personalised federated machine learning models. We first adapt the publicly available OPPORTUNITY dataset to simulate OCD behaviour. Secondly, we evaluate two existing personalised federated learning algorithms against baseline approaches. Finally, we propose a hybrid approach that merges the two evaluated algorithms and reaches a mean area under the precision-recall curve (AUPRC) of 0.954 across clients.
Differentially Private Federated Learning for Anomaly Detection in EHealth Networks. Cholakoska, Ana; Pfitzner, Bjarne; Gjoreski, Hristijan; Rakovic, Valentin; Arnrich, Bert; Kalendar, Marija in UbiComp ’21 (2021). 514–518.
Increasing number of ubiquitous devices are being used in the medical field to collect patient information. Those connected sensors can potentially be exploited by third parties who want to misuse personal information and compromise the security, which could ultimately result even in patient death. This paper addresses the security concerns in eHealth networks and suggests a new approach to dealing with anomalies. In particular we propose a concept for safe in-hospital learning from internet of health things (IoHT) device data while securing the network traffic with a collaboratively trained anomaly detection system using federated learning. That way, real time traffic anomaly detection is achieved, while maintaining collaboration between hospitals and keeping local data secure and private. Since not only the network metadata, but also the actual medical data is relevant to anomaly detection, we propose to use differential privacy (DP) for providing formal guarantees of the privacy spending accumulated during the federated learning.
Data Augmentation of Kinematic Time-Series From Rehabilitation Exercises Using GANs. Albert, Justin; Glöckner, Pawel; Pfitzner, Bjarne; Arnrich, Bert (2021). 1–6.
Machine learning, especially deep learning, offers great potential for medical applications. However, deep learning algorithms need a vast amount of training data. Especially in the medical domain, it is challenging to collect larger datasets. Access to patients can be limited, and data recording is mainly bound to laboratory settings requiring expertise from medical professionals. When involving a healthy control group, datasets are often unbalanced, with most data belonging to the control group. This paper proposes a data augmentation method to generate pose data of repetitive rehabilitation exercises trained on a specific population, e.g., a specific neurological disease. Our method is based on a generative adversarial network (GAN) that uses convolutional and long short-term memory (LSTM) layers. We evaluated our method using a dataset that contains rehabilitation exercises from stroke and Parkinson’s disease patients and a healthy control group. We demonstrated that a classifier trained using our augmentation method could distinguish between healthy, stroke, and Parkinson’s disease patients with an accuracy of 81%. In contrast, the same classifier achieved only 75% when using a standard resampling technique.
Tangle Ledger for Decentralized Learning. Schmid, R.; Pfitzner, B.; Beilharz, J.; Arnrich, B.; Polze, A. (2020). 852–859.
Federated learning has the potential to make machine learning applicable to highly privacy-sensitive domains and distributed datasets. In some scenarios, however, a central server for aggregating the partial learning results is not available. In fully decentralized learning, a network of peer-to-peer nodes collaborates to form a consensus on a global model without a trusted aggregating party. Often, the network consists of Internet of Things (IoT) and Edge computing nodes.Previous approaches for decentralized learning map the gradient batching and averaging algorithm from traditional federated learning to blockchain architectures. In an open network of participating nodes, the threat of adversarial nodes introducing poisoned models into the network increases compared to a federated learning scenario which is controlled by a single authority. Hence, the decentralized architecture must additionally include a machine learning-aware fault tolerance mechanism to address the increased attack surface.We propose a tangle architecture for decentralized learning, where the validity of model updates is checked as part of the basic consensus. We provide an experimental evaluation of the proposed architecture, showing that it performs well in both model convergence and model poisoning protection.
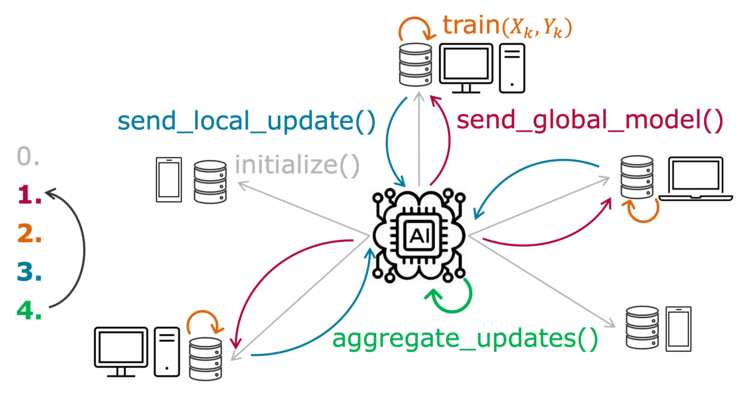
Federated Learning in a Medical Context: A Systematic Literature Review. Pfitzner, Bjarne; Steckhan, Nico; Arnrich, Bert in ACM Transactions on Internet Technology (TOIT) Special Issue on Security and Privacy of Medical Data for Smart Healthcare (2020).
Data privacy is a very important issue. Especially in fields like medicine, it is paramount to abide by the existing privacy regulations to preserve patients’ anonymity. On the other hand, data is required for research and training machine learning models that could help gain insight into complex correlations or personalised treatments that may otherwise stay undiscovered. Those models generally scale with the amount of data available, but the current situation often prohibits building large databases across sites. So it would be beneficial to be able to combine similar or related data from different sites all over the world while still preserving data privacy. Federated learning has been proposed as a solution for this, because it relies on the sharing of machine learning models, instead of the raw data itself. That means private data never leaves the site or device it was collected on. Federated learning is an emerging research area and many domains have been identified for the application of those methods. This systematic literature review provides an extensive look at the concept of and research into federated learning and its applicability for confidential healthcare datasets.
Poisoning Attacks with Generative Adversarial Nets. Muñoz-González, Luis; Pfitzner, Bjarne; Russo, Matteo; Carnerero-Cano, Javier; Lupu, Emil C (2019).
Machine learning algorithms are vulnerable to poisoning attacks: An adversary can inject malicious points in the training dataset to influence the learning process and degrade the algorithm’s performance. Optimal poisoning attacks have already been proposed to evaluate worst-case scenarios, modelling attacks as a bi-level optimization problem. Solving these problems is computationally demanding and has limited applicability for some models such as deep networks. In this paper we introduce a novel generative model to craft systematic poisoning attacks against machine learning classifiers generating adversarial training examples, i.e. samples that look like genuine data points but that degrade the classifier’s accuracy when used for training. We propose a Generative Adversarial Net with three components: generator, discriminator, and the target classifier. This approach allows us to model naturally the detectability constrains that can be expected in realistic attacks and to identify the regions of the underlying data distribution that can be more vulnerable to data poisoning. Our experimental evaluation shows the effectiveness of our attack to compromise machine learning classifiers, including deep networks.
Unobtrusive Measurement of Blood Pressure During Lifestyle Interventions. Morassi Sasso, Ariane; Datta, Suparno; Pfitzner, Bjarne; Zhou, Lin; Steckhan, Nico; Boettinger, Erwin; Arnrich, Bert (2019).
Hypertension is one of the most prevalent chronic diseases worldwide. Early diagnosis of this condition can prevent the incidence of stroke and also, cardiovascular diseases (CVDs) such as myocardial infarction and heart failure. Lifestyle interventions, such as intermittent fasting (IF), aim to lower blood pressure (BP) levels and increase the health of patients with cardiometabolic conditions. However, for monitoring BP, we still rely on a cuff that slows the �ow of blood, which is both uncomfortable and makes continuous monitoring implausible. Recent research has shown that BP can be estimated using comfortable sensors such as the photoplethysmography (PPG) and the electrocardiography (ECG). Features that can be used for the estimation of BP are systolic upstroke time (SUT) and diastolic time (DT) extracted from the PPG signal, and pulse arrival and transit time (PAT/PTT) derived from the combination of ECG and PPG signals. In this paper we present: (1) a study design to collect continuous physiological signals, before and after a 7-days intermittent fasting (IF) intervention from both cardiometabolic and non-hypertensive patients using wearable devices and (2) initial results for predicting continuous blood pressure from the PPG and ECG signals using statistical and machine learning methods.