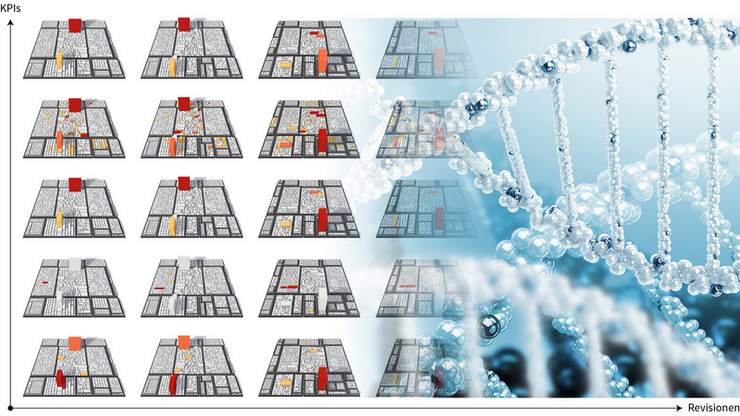
In today's software development process, day to day development on software systems is digitally captured (project management, bug tracking, version control, build and test pipelines). This data can be extracted and processed using process mining and software data mining techniques. This data is complex in its structure and massive in volume, as well as subject to constant change. Analytical or visual results for monitoring or managing software development processes can then be derived from this data.
The publicly funded project "Software DNA" investigates the use of Machine Learning and Visual Analytics techniques on software data. On the basis of a continuous evaluation of characteristics of complex software systems and the IT development processes associated with them, a statistical model is derived that enables a formal consideration of various issues. Through subsequent predictive and prescriptive analyses, knowledge of the generated knowledge base is effectively applied to software development processes in industry. Novel visualization methods and asssociated rendering techniques are used to gain insights into the results. Especially similarity of software modules based on their "Software DNA" is captured and forms the basis of effective layouting. This can be used, for example, to address the following specific use cases
- Uncover which code frequently contains errors and slows down developer productivity.
- Recognize outstanding performing teams and transfer their best practice processes to the entire workforce.
- Uncover risks from complex code known only to a single developer (knowledge monopoly).
This project is funded by the European Regional Development Fund (ERDF – or EFRE in German) and the State of Brandenburg (ILB).
Publications
- Atzberger, D., Cech, T., de la Haye, M., Söchting, M., Scheibel, W., Limberger, D., and Döllner, J. (2021a). ¨Software Forest: A visualization of Semantic Similarities in Source Code using a Tree Metaphor.” In Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications – Volume 3 IVAPP, pages 112–122. INSTICC, SciTePress.
- Atzberger, D., Cech, T., Jobst, A., Scheibel, W., Limberger, D., Trapp, M., and Döllner, J. (2022a). “Visualization of Knowledge Distribution across Development Teams using 2.5d Semantic Software Maps.” In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications – Volume 3 IVAPP, pages 210–217. INSTICC, SciTePress.
- Atzberger, D., Cech, T., Scheibel, W., Limberger, D., and Döllner, J. (2023a). “Visualization of Source Code Similarity using 2.5d Semantic Software Maps.” VISIGRAPP 2021: Computer Vision, Imaging and Computer Graphics Theory and Applications, pages 162–182.
- Atzberger, D., Cech, T., Scheibel, W., Limberger, D., Trapp, M., and Döllner, J. (2022b). “A Benchmark for the Use of Topic Models for Text Visualization Tasks.” In Proceedings of the 15th International Symposium on Visual Information Communication and Interaction, VINCI ’22, pages 17:1–4. ACM.
- Atzberger, D., Scheibel, W., Limberger, D., and Döllner, J. (2021b). “Software Galaxies: Displaying Coding Activities using a Galaxy Metaphor.” In Proceedings of the 14th International Symposium on Visual Information Communication and Interaction, VINCI ’21, pages 18:1–2. ACM.
- Atzberger, D., Schneider, J., Scheibel, W., Limberger, D., Trapp, M., and Döllner, J. (2022c). “Mining Developer Expertise from Bug Tracking Systems using the Author Topic Model.” In Proceedings of the 17th International Conference on Evaluation of Novel Approaches to Software Engineering, ENASE ’22, pages 107–118. INSTICC, SciTePress.
- Atzberger, D., Schneider, J., Scheibel, W., Trapp, M., and Döllner, J. (2023b). “Evaluating Probabilistic Topic Models for Bug Triaging Tasks” ENASE 2022: Revised Selected Papers. in press.
- Atzberger, D., Scordialo, N., Cech, T., Scheibel, W., Trapp, M., and Döllner, J. (2022d). “CodeCV: Mining Expertise of Github Users from Coding Activities.” In Proceedings of the 22nd International Working Conference on Source Code Analysis and Manipulation, SCAM ’22. IEEE.
- Büsemeyer, M., Limberger, D., Scheibel, W., and Döllner, J. (2021). “Interactive Simulation and Visualization of Long-term, ETF-based Investment Strategies.” In Proceedings of the 14th International Symposium on Visual Information Communication and Interaction, VINCI ’21, pages 5:1–5. ACM.
- Fiedler, C., Scheibel, W., Limberger, D., Trapp, M., and Döllner, J. (2020). “Survey on User Studies on the Effectiveness of Treemaps.” In Proceedings of the 13th International Symposium on Visual Information Communication and Interaction, VINCI ’20, pages 2:1–10. ACM.
- Heseding, F., Scheibel, W., Limberger, D., and Döllner, J. (2022). “Tooling for Time- and Space-efficient Git Repository Mining.” In Proceedings of the 19th International Conference on Mining Software Repositories – Data and Tool Showcase Track, MSR ’22. ACM.
- Jobst, A., Atzberger, D., Cech, T., Scheibel, W., Trapp, M., and Döllner, J. (2022). “Efficient Github Crawling using the GraphQL API.” In Proceedings of the 22th International Conference on Computational Science and Its Applications, ICCSA ’22, pages 662–677. Springer.
- Limberger, D., Scheibel, W., Döllner, J., and Trapp, M. (2022a). “Visual Variables and Configuration of Software Maps.” Journal of Visualization. Springer.
- Limberger, D., Scheibel, W., van Diecken, J., and Döllner, J. (2022b). “Procedural Texture Patterns for Encoding Changes in Color in 2.5d Treemap Visualizations.” Journal of Visualization. Springer.
- Limberger, D., Scheibel, W., van Dieken, J., and Döllner, J. (2021). “Visualization of Data Changes in 2.5d Treemaps using Procedural Textures and Animated Transitions.” In Proceedings of the 14th International Symposium on Visual Information Communication and Interaction, VINCI ’21, pages 6:1–5. ACM.
- Otto, P., Limberger, D., and Döllner, J. (2020). “Physically-based Environment and Area Lighting using Progressive Rendering in WebGL.” In Proceedings of the 25th International Conference on 3D Web Technology, Web3D ’20, pages 15:1–9. ACM.
- Scheibel, W., Limberger, D., and Döllner, J. (2020). “Survey of Treemap Layout Algorithms.” In Proceedings of the 13th International Symposium on Visual Information Communication and Interaction, VINCI ’20, pages 1:1–9. ACM.
- Scheibel, W., Weyand, C., Bethge, J., and Döllner, J. (2021). “Algorithmic Improvements on Hilbert and Moore Treemaps for Visualization of Large Tree-structured Datasets.” In Proceedings of the 23rd EG Conference on Visualization, EuroVis ’21, pages 115–119. EG.
- Thiede, C., Scheibel, W., Limberger, D., and Döllner, J. (2022). “Augmenting Library Development by Mining Usage Data from Downstream Dependencies.” In Proceedings of the 17th International Conference on Evaluation of Novel Approaches to Software Engineering, ENASE ’22, pages 221–232. INSTICC, SciTePress.
- Wagner, L., Limberger, D., Scheibel, W., and Döllner, J. (2022). “Hardware-accelerated Rendering of Web-based 3D Scatter Plots with Projected Density Fields and Embedded Controls.” In Proceedings of the 27th International Conference on 3D Web Technology, Web3D ’22. ACM.