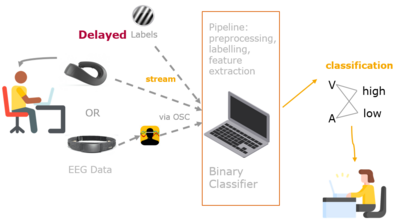
Towards Multi-Modal Recordings in Daily Life: A Baseline Assessment of an Experimental Framework Anders, Christoph; Moontaha, Sidratul; Arnrich, Bert in IS (2022). (Vol. H) 27–30. Information Society.
Background: Wearable devices can record physiological signals from humans to enable an objective assessment of their Mental State. In the future, such devices will enable researchers to work on paradigms outside, rather than only inside, of controlled laboratory environments. This transition requires a paradigm shift on how experiments are conducted, and introduces new challenges. Method: Here, an experimental framework for multi-modal baseline assessments is presented. The developed test battery covers stimuli and questionnaire presenters, and multi-modal data can be recorded in parallel, such as Photoplethysmography, Electroencephalography, Acceleration, and Electrodermal Activity data. The multi-modal data is extracted using a single platform, and synchronized using a shake detection tool. A baseline was recorded from eight participants in a controlled environment. Using Leave-One-Out Cross-Validation, the resampling of data, the ideal window size, and the applicability of Deep Learning for Mental Workload Classification were evaluated. In addition, participants were polled on the acceptance of using the wearable devices. Results: The binary classification performance declined by an average of 7.81% when using eye-blink removal, underlining the importance of data synchronization, correct artefact identification, evaluating and developing artefact removal techniques, and investigating on the robustness of the multi-modal setup. Experiments showed that the optimal window size for the acquired data is 30 seconds for Mental Workload classification, with which a Random Forest classifier and an optimized Deep Convolutional Neural Network achieved the best-balanced classification accuracy of 70.27% and 74.16%, respectively. Conclusions: This baseline assessment gives valuable insights on how to prototype stimulus presentation with different wearable devices and suggests future work packages, paving the way for researchers to investigate new paradigm outside of controlled environments.
Further Information
AbstractBackground: Wearable devices can record physiological signals from humans to enable an objective assessment of their Mental State. In the future, such devices will enable researchers to work on paradigms outside, rather than only inside, of controlled laboratory environments. This transition requires a paradigm shift on how experiments are conducted, and introduces new challenges. Method: Here, an experimental framework for multi-modal baseline assessments is presented. The developed test battery covers stimuli and questionnaire presenters, and multi-modal data can be recorded in parallel, such as Photoplethysmography, Electroencephalography, Acceleration, and Electrodermal Activity data. The multi-modal data is extracted using a single platform, and synchronized using a shake detection tool. A baseline was recorded from eight participants in a controlled environment. Using Leave-One-Out Cross-Validation, the resampling of data, the ideal window size, and the applicability of Deep Learning for Mental Workload Classification were evaluated. In addition, participants were polled on the acceptance of using the wearable devices. Results: The binary classification performance declined by an average of 7.81% when using eye-blink removal, underlining the importance of data synchronization, correct artefact identification, evaluating and developing artefact removal techniques, and investigating on the robustness of the multi-modal setup. Experiments showed that the optimal window size for the acquired data is 30 seconds for Mental Workload classification, with which a Random Forest classifier and an optimized Deep Convolutional Neural Network achieved the best-balanced classification accuracy of 70.27% and 74.16%, respectively. Conclusions: This baseline assessment gives valuable insights on how to prototype stimulus presentation with different wearable devices and suggests future work packages, paving the way for researchers to investigate new paradigm outside of controlled environments.
Quantifying Cognitive Load from Voice using Transformer-Based Models and a Cross-Dataset Evaluation. Hecker, Pascal; Kappattanavar, Arpita M.; Schmitt, Maximilian; Moontaha, Sidratul; Wagner, Johannes; Eyben, Florian; Schuller, Björn W.; Arnrich, Bert (2022). 337–344.
Cognitive load is frequently induced in laboratory setups to measure responses to stress, and its impact on voice has been studied in the field of computational paralinguistics. One dataset on this topic was provided in the Computational Paralinguistics Challenge (ComParE) 2014, and therefore offers great comparability. Recently, transformer-based deep learning architectures established a new state-of-the-art and are finding their way gradually into the audio domain. In this context, we investigate the performance of popular transformer architectures in the audio domain on the ComParE 2014 dataset, and the impact of different pre-training and fine-tuning setups on these models. Further, we recorded a small custom dataset, designed to be comparable with the ComParE 2014 one, to assess cross-corpus model generalisability. We find that the transformer models outperform the challenge baseline, the challenge winner, and more recent deep learning approaches. Models based on the ‘large’ architecture perform well on the task at hand, while models based on the ‘base’ architecture perform at chance level. Fine-tuning on related domains (such as ASR or emotion), before fine-tuning on the targets, yields no higher performance compared to models pre-trained only in a self-supervised manner. The generalisability of the models between datasets is more intricate than expected, as seen in an unexpected low performance on the small custom dataset, and we discuss potential ‘hidden’ underlying discrepancies between the datasets. In summary, transformer-based architectures outperform previous attempts to quantify cognitive load from voice. This is promising, in particular for healthcare-related problems in computational paralinguistics applications, since datasets are sparse in that realm.
Further Information
AbstractCognitive load is frequently induced in laboratory setups to measure responses to stress, and its impact on voice has been studied in the field of computational paralinguistics. One dataset on this topic was provided in the Computational Paralinguistics Challenge (ComParE) 2014, and therefore offers great comparability. Recently, transformer-based deep learning architectures established a new state-of-the-art and are finding their way gradually into the audio domain. In this context, we investigate the performance of popular transformer architectures in the audio domain on the ComParE 2014 dataset, and the impact of different pre-training and fine-tuning setups on these models. Further, we recorded a small custom dataset, designed to be comparable with the ComParE 2014 one, to assess cross-corpus model generalisability. We find that the transformer models outperform the challenge baseline, the challenge winner, and more recent deep learning approaches. Models based on the ‘large’ architecture perform well on the task at hand, while models based on the ‘base’ architecture perform at chance level. Fine-tuning on related domains (such as ASR or emotion), before fine-tuning on the targets, yields no higher performance compared to models pre-trained only in a self-supervised manner. The generalisability of the models between datasets is more intricate than expected, as seen in an unexpected low performance on the small custom dataset, and we discuss potential ‘hidden’ underlying discrepancies between the datasets. In summary, transformer-based architectures outperform previous attempts to quantify cognitive load from voice. This is promising, in particular for healthcare-related problems in computational paralinguistics applications, since datasets are sparse in that realm.
Towards Multi-Modal Recordings in Daily Life: A Baseline Assessment of an Experimental Frame- work. Moontaha, Sidratul; Anders, Christoph; Arnrich, Bert (2022). 27–30.
Quantifying Cognitive Load from Voice using Transformer-Based Models and a Cross-Dataset Evaluation. Hecker, Pascal; Kappattanavar, Arpita M; Schmitt, Maximilian; Moontaha, Sidratul; Wagner, Johannes; Eyben, Florian; Schuller, Björn W; Arnrich, Bert (2022). 337–344.