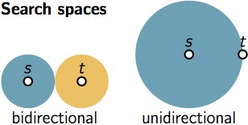
One approach to bridge this gap between theory and practice is to make an average-case analysis by bounding the expected run time under the assumption that the input is randomly drawn from a certain distribution. The practical relevance and explanatory power of such an average-case analysis of course heavily depends on the assumed probability distribution of the input. In case of the bidirectional search, it is actually known that it has a significantly sublinear run time on numerous random graph models [1]. However, the analysis heavily relies on the fact that the edges in the random models under consideration are statistically independent. Unfortunately, this is a very unrealistic assumption: in a social network, two friends of a single person are much more likely to be friends of each other than two random people. Thus, the question why bidirectional search performs so well on large real-world networks remains unanswered.
Purpose of the Project
We want to theoretically explain why the bidirectional search performs so well on large real-world networks. To this end, we want to bound its expected run time on a more realistic model for such networks, namely on hyperbolic random graphs.
Hyperbolic Random Graphs
When thinking of complex real-world networks, there are two fundamental properties that come to mind. First, they are typically heterogeneous, i.e., they usually have some high-degree and many low-degree vertices (think of few very popular and many "normal" people in a social network). In fact, many real-world networks are scale-free, which means that the number of vertices of degree at most \(x\) is roughly proportional to \(x^{−\beta}\). One also says that such graphs have a power-law degree distribution with power-law exponent \(\beta\). Second, vertices with a common neighbor should be more likely to be connected than vertices without common neighbors. Formally, this property can be expressed via the so-called clustering coefficient, which, roughly speaking, is the probability that two vertices with a common neighbor are connected.