Implicit Model Specialization through Dag-Based Decentralized Federated Learning. Beilharz, Jossekin; Pfitzner, Bjarne; Schmid, Robert; Geppert, Paul; Arnrich, Bert; Polze, Andreas in Middleware ’21 (2021). 310–322.
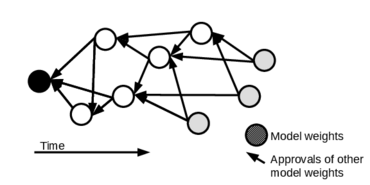
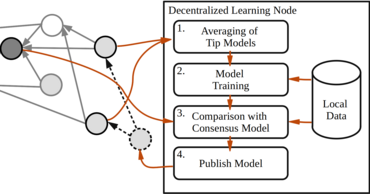
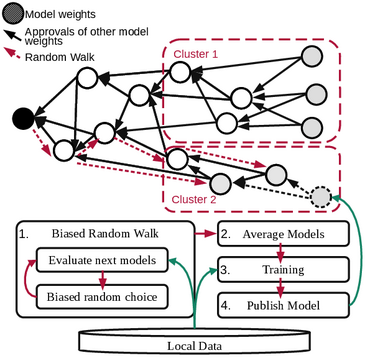
Federated learning allows a group of distributed clients to train a common machine learning model on private data. The exchange of model updates is managed either by a central entity or in a decentralized way, e.g. by a blockchain. However, the strong generalization across all clients makes these approaches unsuited for non-independent and identically distributed (non-IID) data.We propose a unified approach to decentralization and personalization in federated learning that is based on a directed acyclic graph (DAG) of model updates. Instead of training a single global model, clients specialize on their local data while using the model updates from other clients dependent on the similarity of their respective data. This specialization implicitly emerges from the DAG-based communication and selection of model updates. Thus, we enable the evolution of specialized models, which focus on a subset of the data and therefore cover non-IID data better than federated learning in a centralized or blockchain-based setup.To the best of our knowledge, the proposed solution is the first to unite personalization and poisoning robustness in fully decentralized federated learning. Our evaluation shows that the specialization of models emerges directly from the DAG-based communication of model updates on three different datasets. Furthermore, we show stable model accuracy and less variance across clients when compared to federated averaging.
Tangle Ledger for Decentralized Learning. Schmid, R.; Pfitzner, B.; Beilharz, J.; Arnrich, B.; Polze, A. (2020). 852–859.
Federated learning has the potential to make machine learning applicable to highly privacy-sensitive domains and distributed datasets. In some scenarios, however, a central server for aggregating the partial learning results is not available. In fully decentralized learning, a network of peer-to-peer nodes collaborates to form a consensus on a global model without a trusted aggregating party. Often, the network consists of Internet of Things (IoT) and Edge computing nodes.Previous approaches for decentralized learning map the gradient batching and averaging algorithm from traditional federated learning to blockchain architectures. In an open network of participating nodes, the threat of adversarial nodes introducing poisoned models into the network increases compared to a federated learning scenario which is controlled by a single authority. Hence, the decentralized architecture must additionally include a machine learning-aware fault tolerance mechanism to address the increased attack surface.We propose a tangle architecture for decentralized learning, where the validity of model updates is checked as part of the basic consensus. We provide an experimental evaluation of the proposed architecture, showing that it performs well in both model convergence and model poisoning protection.