Cloud-Native Database Systems and Unikernels: Reimagining OS Abstractions for Modern Hardware
Summary written by Till Prochaska
In his lecture [1], Prof. Dr. Viktor Leis of the Technical University of Munich (TUM) presents his research on adopting unikernel operating systems (OSs) for Database Management Systems (DBMSs).
On an abstract level, both OSs and DBMSs implement similar functionality to manage compute, memory, I/O, and caching. In practice, however, many of the interfaces provided by OSs are poorly suited for use in DBMSs, frequently requiring developers to reimplement functionality in the DBMS.
So far, optimizing DBMS performance has often required either modifying the OS (e.g., using custom Linux kernel modules) or bypassing the kernel. Both options require significant engineering effort and are difficult to maintain, primarily due to the complexity of legacy OS interfaces, requirements to support legacy and non-standard hardware, and process isolation.
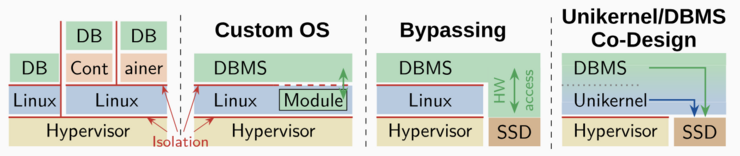
As an alternative, Leis proposes using unikernel OSs for DBMSs. Unlike traditional OSs (such as Linux), unikernels are designed to run only a single process in a single address space. This approach significantly reduces complexity and overhead, allowing for optimizations that have previously been unfeasible. As virtualization is now common due to the prevalence of cloud deployments, and Database-as-a-service (DBaaS) offerings are becoming increasingly popular, unikernels have become a promising and realistic approach for running DBMSs in the cloud.
1) The Uneasy Relationship Between Operating Systems and DBMSs
Leis presents three case studies to illustrate what he calls “the uneasy relationship between operating systems and DBMSs”.
Case Study 1: Virtual Memory
DBMSs typically cache data in memory. mmap is a Linux system call that maps files from storage into memory. Applications access a file as if it were fully loaded into memory. The OS doesn’t load the entire file into memory at once. Instead, it loads pages (fixed-size chunks of data) into memory on-demand. When a page fault (access to a page that hasn’t been loaded into memory) occurs, the OS lazily loads the page from storage. Subsequent accesses to cached pages are faster. The OS also handles page eviction (removing pages from memory to free up space). All of this is handled transparently by the OS, and the application has limited ways to control the caching behavior.
While this seems like a useful abstraction, Leis refers to research that shows that mmap has multiple issues that make it unsuitable for use in DBMSs, many of them related to mmap’s transparent nature [2]:
- Transactional safety. As the DBMS has no control over when pages are evicted from memory, safe transaction handling becomes more complex.
- IO stalls. The DBMS cannot predict whether accessing a page will be fast or result in a page fault, making optimizations (such as prefetching) impossible without workarounds.
- Error handling. Handling of I/O errors becomes more complex. Any code accessing memory-mapped data may raise I/O errors that need to be handled properly by DBMS developers.
- Performance issues. mmap is inefficient when working with larger-than-memory datasets.
While workarounds for some of these issues exist, they require careful implementation, defeating the purpose of using mmap in the first place: reducing complexity by leveraging OS-level abstractions. Due to these drawbacks, most DBMSs do not use mmap and instead implement their own user-space caching mechanisms.
Another approach to this problem is vmcache, a new design for a virtual memory interface [3]. In contrast to mmap, vmcache gives DBMSs control over page faults and eviction, while still making use of hardware-supported translation of virtual memory addresses. However, a performant implementation of this approach required implementing a custom Linux kernel module, adding significant complexity and maintenance overhead.
Case Study 2: Storage I/O
Modern SSDs are so fast that accessing them efficiently is critical. Leis presents a microbenchmark that compares I/O operations per second (IOPS) and CPU utilization for 4K-page reads from SSD storage across different I/O interfaces, including synchronous POSIX I/O (pread), asynchronous I/O (io_uring), and the Intel Storage Performance Development Kit (SPDK), a set of low-level libraries for user-space I/O which completely bypasses the kernel.
In contrast to the baseline of using pread, io_uring was able to achieve maximum IOPS, although only when most OS features (such as the file system, RAID) were disabled. Furthermore, it also caused significant CPU overhead just for the I/O, leaving little room for any actual data processing.
Compared to io_uring, using SPDK significantly reduced the CPU overhead while still achieving the same number of IOPS. The main drawback of SPDK is its low-level interfaces, i.e. developers cannot rely on OS features such as the file system.
Again, this shows that the abstractions of a traditional OS prevent fully exploiting modern hardware capabilities.
Case Study 3: Scheduling
LeanStore is a storage engine developed at TUM. As modern SSDs are highly parallel devices, DBMSs have to perform many I/O tasks in parallel to fully exploit SSD bandwidth. Because OS threads come with significant overhead, LeanStore implements its own lightweight user-space scheduling mechanism [4]. However, running entirely in user space has drawbacks compared to OS-level threading, such as the lack of preemption (a thread cannot be stopped unless it explicitly yields control back to the scheduler).
2) Models of DBMS/OS Interaction
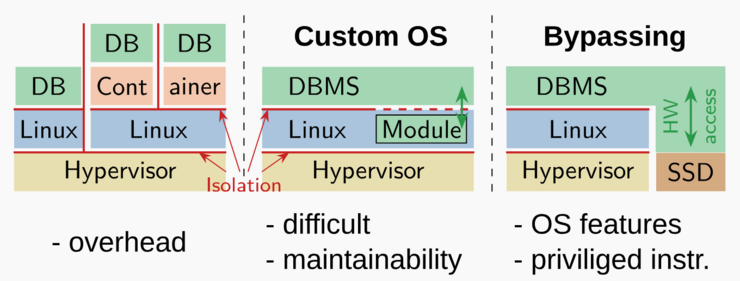
These case studies demonstrate three different models of interaction between DBMSs and OSs.
In the standard model, the DBMS runs as an application within the OS. Today, DBMSs are often deployed in the cloud, which typically means that the OS itself runs within a virtual machine managed by a hypervisor. In some cases, DBMSs may also be containerized. Each of these layers is separated by isolation boundaries. This results in overhead due to redundant isolation and makes it difficult to fully exploit modern hardware.
In such cases, customizing the OS (e.g., using custom Linux kernel modules) can be a workaround to expose additional capabilities (such as direct hardware access) to the DBMS. However, implementing and maintaining OS customizations is difficult and, for that reason, may not be practical.
Finally, entirely bypassing the OS can unlock certain optimizations, but this also means that DBMS developers must reimplement many OS features in user space.
Leis concludes that all three approaches have significant drawbacks, but also emphasizes that these are not an inherent problem of Linux as an OS, but rather a result of legacy OS interfaces, support for legacy and non-standard hardware, and process isolation.
Figure 1: Three different models of DBMS/OS interaction