Context
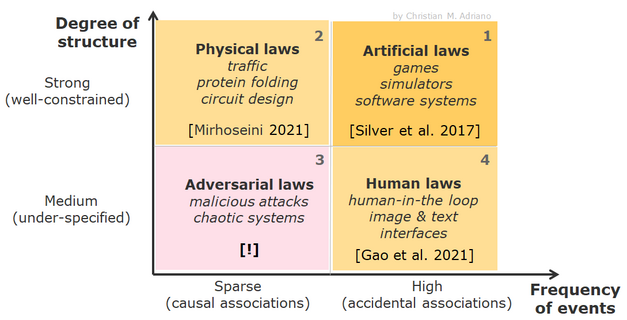
Recently, Alpha Go-Zero [Silver et al. 2017] learned to win the famous game of Go without supervision. Instead, it learned by playing against previous versions of itself. Besides that, as the blue and purple curves here show, the self-play approach achieved higher performance than the previous version of the Alpha-Go. If you recall, the one that defeated the world-champion.
In another recent progress, this Google [Mirhoseini et al. 2021] announced that a reinforcement learning agent was able to design optimal circuit layouts for its TensorFlow chip. A feat that was still beyond the capacity of automated tools.
Real-World Challenges
However, industry surveys report that from 55% to 72% of companies are not being able to deploy AI systems [Algorithmia 2020] [Capgemini 2020].
Probable Reason
Current systems cannot adapt to more complex and evolving realities. Realities that play like strong adversaries against these AI systems. The inability to adapt is a problem of lack of robustness in these AI Systems [Jordan 2019][D’Amour et al. 2020].
Contact
For more information, please contact Christian M. Adriano.