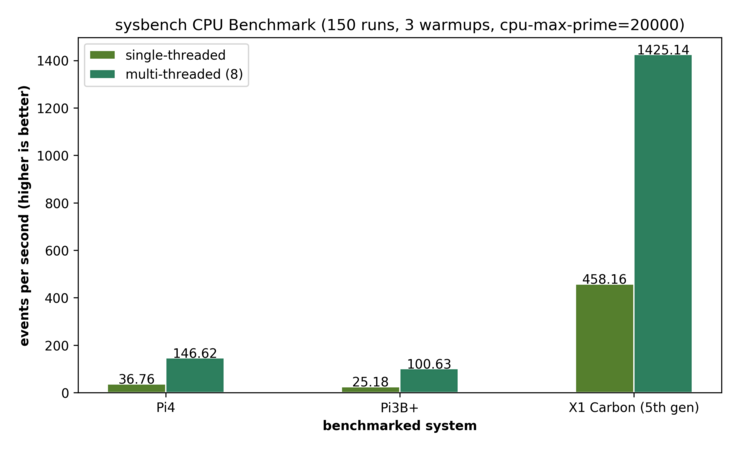
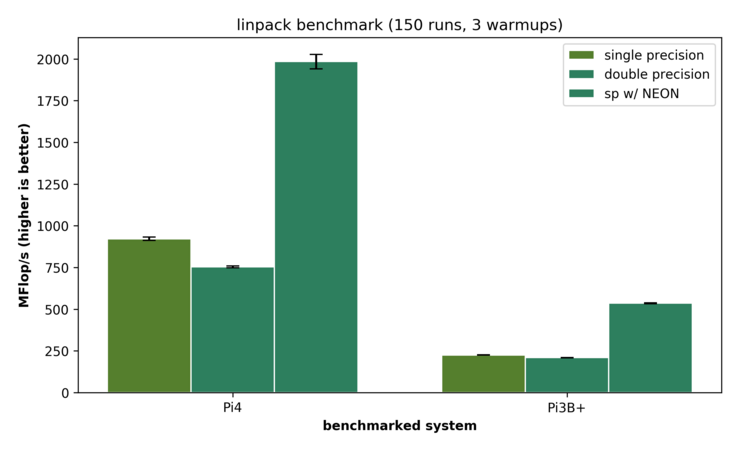
Currently, the cluster benchmark results of this project are to be found in our paper (TBD). Nevertheless, we also evaluated some further individual benchmarks of the Pis and want to share our results here.
IO-Benchmarks
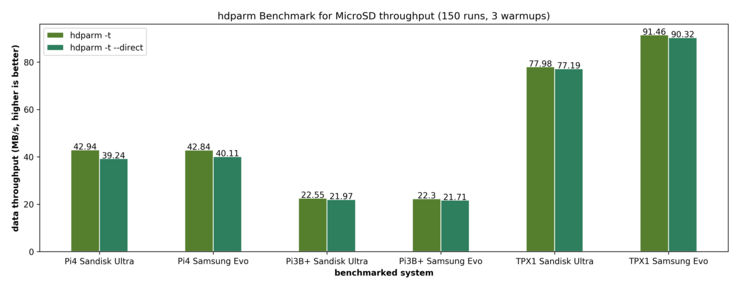
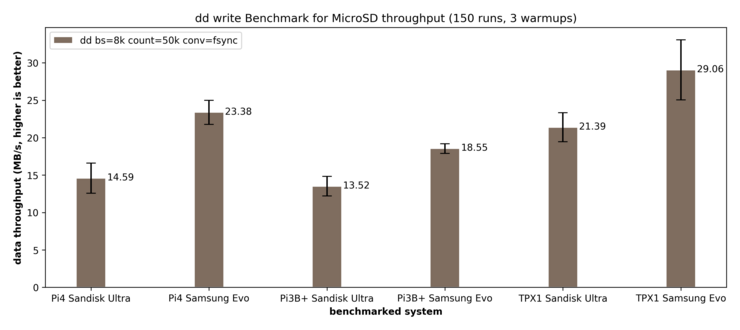
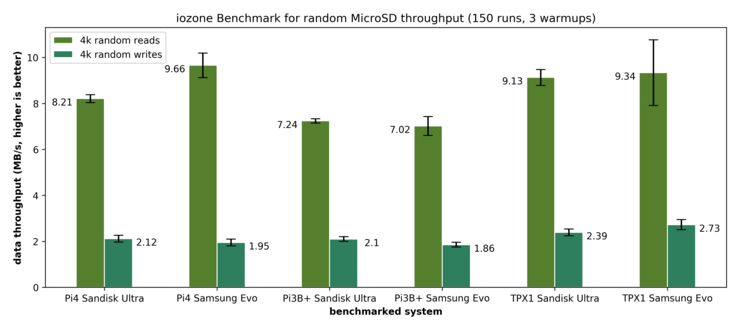
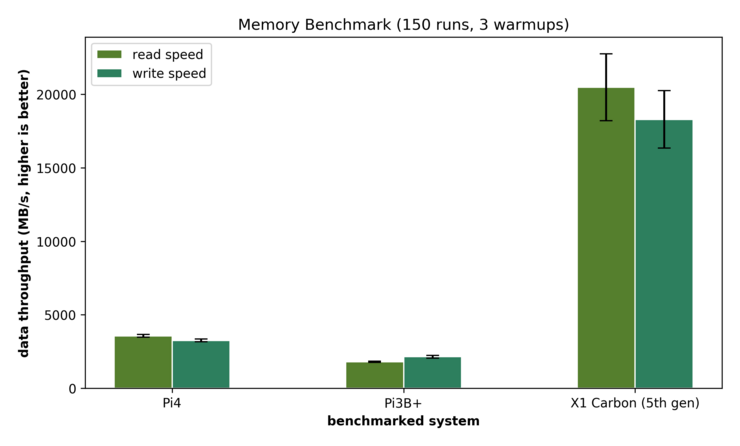
I/O is a key-factor for performance of a cluster that deals with data-intensive tasks. If the bandwidth is too low, the transfer from data into memory can be a huge bottleneck. Thus, we want to gain a understanding on the I/O Performance of our cluster. As a first benchmark of reading speed, we employ hdparm. While mainly being a tool for HDD configuration, it also offers different benchmarking options. While hdparm offers the option to measure the Linux buffer cache read performance (using option -T), we are interested in disk performance. Thus, we are interested into two different benchmarks:
- hdparm -t: In this case we are measuring the buffered disk reads. This means that we are measuring the speed of reading through the buffer cache to the disk without any prior caching of data. We are also using the page cache of the kernel.
- hdparm -t --direct: Using the additional --direct flag, we are measuring the O_DIRECT disk reads. This option employs the kernel's O_DIRECT flag which bypasses the page cache, leading to raw I/O into hdparm's buffers.
We test the Raspberry Pi 4 as well as the Raspberry Pi 3B+. For each model, we test two kinds of MicroSD cards to see if the choice of a SD-card makes a difference: We test the SanDisk Ultra as well as the Samsung Evo. For comparison, we also measure the performance on a USB3.0-MicroSD card reader with a ThinkPad X1 Carbon (2017). The measurements give the following results: