Driven by the increasing volume and velocity of data, stream processing systems have become more and more relevant, not only for tech companies but also for businesses in logistics, finance, and other sectors. Similarly, time-critical business decisions benefit from real-time data analytics. Modern hardware lays the technical foundation for such analytics. Entry hurdles for end users are lowered through cloud computing and analytical systems such as Spark Streaming and Flink. Today, it is easier than ever before to capitalize on real-time analytics.
What is Real-Time Analytics?
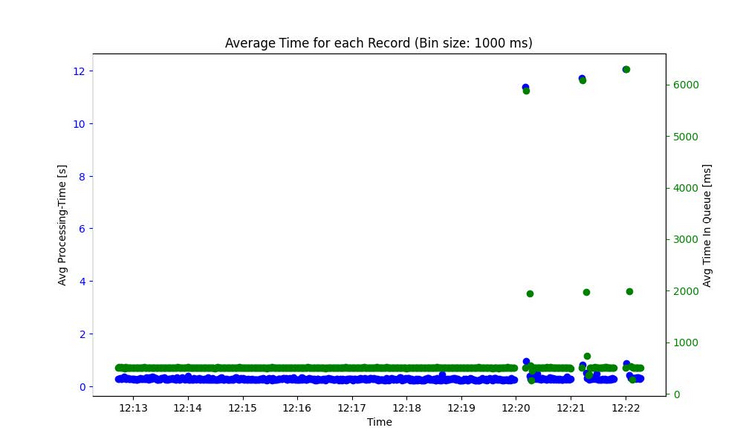
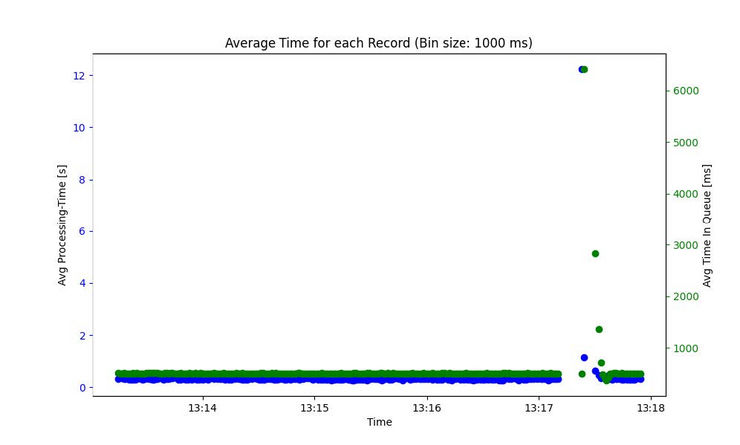
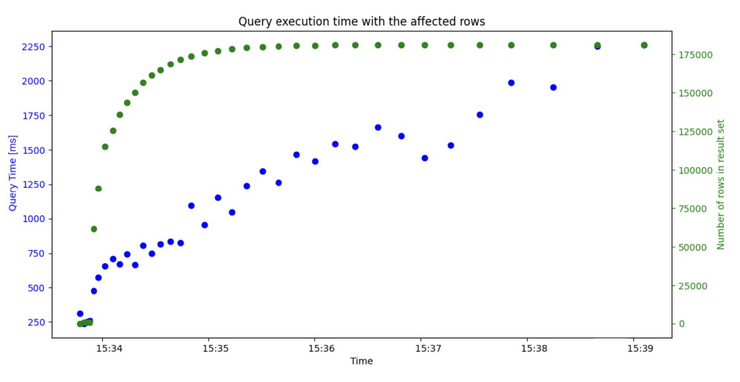
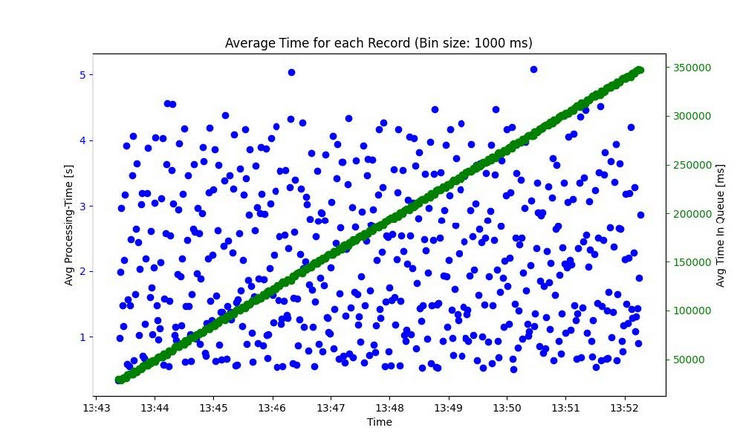
Real-time analytics involves using data as soon as it is produced to reason business decisions. Systems need to execute analytical queries, incorporating fresh data. Two metrics are particularly important in this context: - Data Latency: Data latency measures the time it takes for generated data to become visible in a query. For real-time analytics systems, the goal is to minimize this time span during which the data is processed by the systems. Therefore, data should be visible within a few seconds or even sub-seconds. - Query Latency: Query latency is the time it takes for queries to execute and return the result set. Although there are options for quickly inserting data, in the past this has resulted in long query latency. The goal of real-time analytics systems is to minimize query latency and quickly reflect changes in the data. This enables faster business decisions, real-time predictions, and process automation.
The Current State of Benchmarks
Despite the availability of benchmarks such as TPC-H and StarSchema Benchmark (SSB) to assess OLAP system performance, none of these benchmarks adequately address the unique challenges posed by real-time analytics, such as data freshness and streaming ingest capabilities. At the opposite end of the spectrum lie streaming benchmarks, which focus on assessing the performance of stream processing engines but overlook the critical aspect of analytical queries. Examples of such benchmarks include the LinearRoad Benchmark and the Yahoo Streaming Benchmark. To our knowledge, there is no benchmark that combines these two aspects and measures performance of stream processing engines for relational mixed OLTP-OLAP workloads.
Our Goal
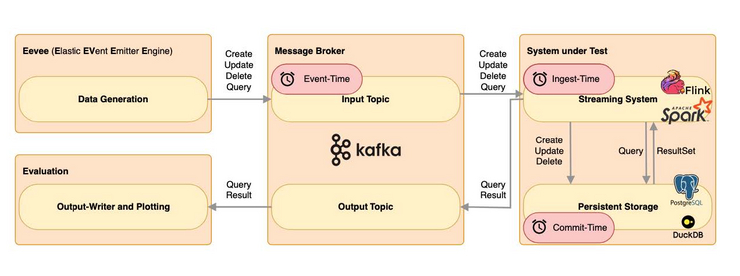
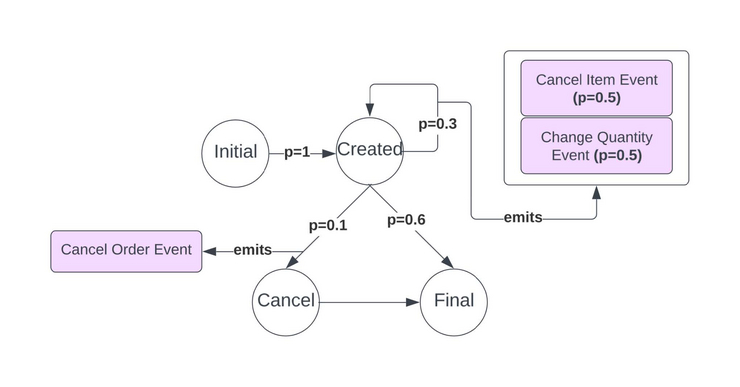
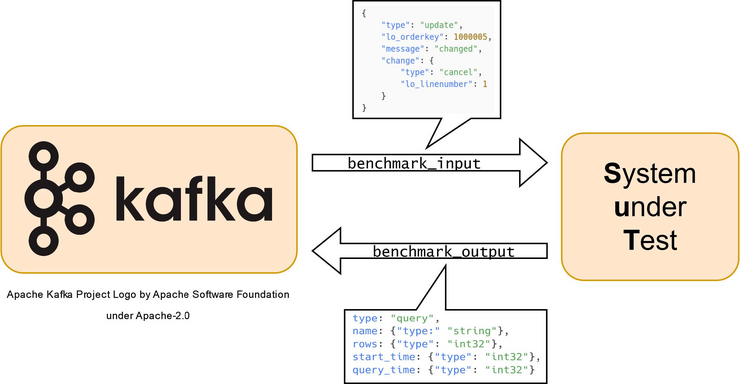
In our master project, we aimed to develop a benchmark specifically designed for realtime analytics systems. The benchmark focuses on data latency and query latency. Our goal was to combine the advantages of streaming systems with a persistent data store, where we can later execute OLAP queries on both the streamed data and the static data. The benchmark must be designed to allow developers of real-time analytics systems to easily test their implementations of different systems, or to find the most efficient implementation for one specific system.
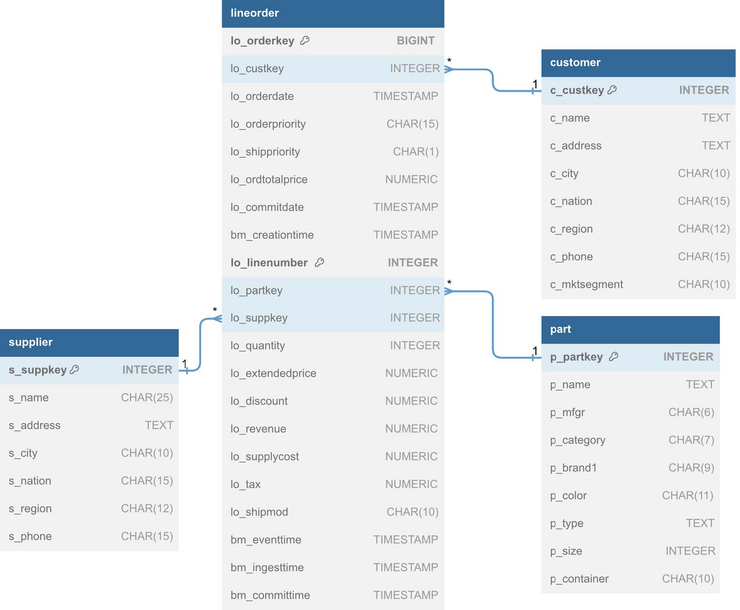
Database Schema
We used the database schema from the StarSchema Benchmark (SSB) as a starting point. The schema includes the customer, part, supplier, and lineorder relations. The latter is a denormalized form of the lineitem and orders table of the well known TPC-H benchmark. Compared to the SSB, we removed the date table and added individual columns for different timestamps, which are labeled with the prefix bm_. Those are used
to track the time spent in the system by each record.
The schema can be seen in the figure below.