Project Outline
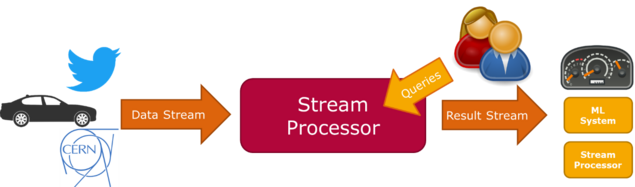
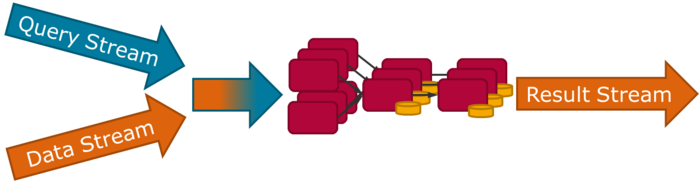
The goal of this master project is to build a prototype of a distributed stream processing engine that has a concept of dynamic query deployment and removal. In this project, a compilation-based approach will be built, with a clear focus on performance. The prototype should be able to process simple stream processing queries and streams. The set of query operators to be supported will be retrieved from benchmarks such as Nexmark [3] and previous implementations. To speed up the processing, the query dataflows needs to be compiled into binaries. The idea is to generate code for the dataflow [8,9] that can run in a distributed setup. For this, a focus is on distribution and efficient handling of networking. Different techniques can be explored, such as remote direct memory access (RDMA) [5]. In a previous master project, students have explored the compilation-based approach for a single node setup. Students can build on the results of this project. In this project, students will learn the inner workings of stream processors and data management systems in general, with a particular focus on distribution and query compilation. It is targeting students interested in acquiring skills in data management, stream processing, data flows, compilers, and low-level systems programming.
General information and an introduction on stream processing can be found in the O’Reilly blog posts by Tyler Akidau [5,6] and the stream processing book [7].