Ralf Herbrich studied Computer Science at Technical University Berlin. He earned his Diploma degree in 1997, focusing on Computer Graphics and Artificial Intelligence (AI), and his PhD degree in 2000, focusing on Theoretical Statistics. Herbrich held positions at well-known tech companies. Apart from doing research himself, he has held managing positions at Microsoft, Facebook, Amazon and Zalando, often leading research teams. Before this, Herbrich worked as a researcher at Microsoft Research and Darwin College, focussing on machine learning as well as other artificial intelligence topics. This includes among others approximate computing, Bayesian inference and decision making, and natural language processing. He has published over 80 peer-reviewed conference and journal papers in these research fields. Since April 2022 Ralf Herbrich has held the chair "Artificial Intelligence and Sustainability" at the Hasso Plattner Institute. There, he has also been collaborating with betteries, a Berlin-based startup working on battery upcycling.
Ralf Herbrich presented his chair's research topics in a lecture as part of the Lecture Series on HPI Research. The following is a summary of his talk.
Lecture Summary
We often gauge a system's intelligence by comparing its performance to a human's. When we interact with a machine from a distance, and it appears like we are interacting with a human, we refer to it as artificially intelligent.
There are various approaches to achieving artificial intelligence (AI). One fundamental approach is machine learning. The concept is that we want a computer program to learn from past experiences. More formally, we have a task we want to achieve, a performance measure that tells us how well the program performs at this specific task, and some previous experience. The task is often called a prediction, the performance measure is called a loss function, and the experience is called training data. A program learns if it performs better using its prior experience.
Classification problems are a prevalent use case for machine learning. These problems involve a finite set of predefined classes. Given some input, we want to determine which class it belongs to. For instance, we might want to read hand-written postal codes. We could process each digit individually and use a machine-learning algorithm to identify it. In this scenario, the input would be a hand-written digit, and the classes would be the digits from zero to nine.
Another use case is regression. In regression, we are interested in the relationship between variables. Given the values of one or more variables, we want to estimate the value of another variable. Temperature predictions in a weather forecast are an example of such a task: Given a history of sensor data, we estimate a temperature in the future. The chair focuses on probabilistic machine learning, a specific form of machine learning. The goal is to build an algorithm that takes a point from the input space and outputs a point from the output space.
The chair focuses on probabilistic machine learning, a specific form of machine learning. The goal is to build an algorithm that takes a point from the input space and outputs a point from the output space.
Many functions could describe the relationship between the input and output spaces. The hypothesis space is the set of these possible functions. Our objective is to find the function of the hypothesis space that most accurately describes the relationship. To achieve this, we require:
- The hypothesis space.
- Prior beliefs. We may already have some assumptions about how likely each function is. We can make use of these assumptions and call them our prior beliefs.
- Training data. Training data demonstrates how the input space relates to the output space.
- The likelihood function. A likelihood function takes the training data and a function from the hypothesis space as inputs. Then, it determines the likelihood of the function being correct based on the training data. It computes this as the probability of observing our training data, assuming that this function accurately describes the relationship between the input and output spaces.
Statistics provides the tools for deriving the best function from the hypothesis space. Namely, these are:
- Maximum Likelihood (ML) if we want to avoid considering prior beliefs.
- Maximum A Posterior (MAP) for considering our prior beliefs.
Probabilistic machine learning offers two primary advantages. First, it describes learning as optimization in the hypothesis space. Second, storing the algorithm means only storing the function's parameters (i.e., its coordinates) in the hypothesis space. However, this approach has a limitation. We can only find a single best function from the hypothesis space.
Using probabilistic machine learning, we can answer the following key questions:
- Given a prediction, some input, and training data, how likely is the prediction correct?
- Given some input and training data, what is the best prediction?
Deep learning is a field that strongly relates to probabilistic machine learning. In deep learning, the functions of the hypothesis space take the form of an artificial neural network (ANN). An ANN comprises artificial neurons. A neuron takes a vector and outputs a single scalar value. It computes this scalar value by first calculating the weighted sum of the input values. For this, each neuron has a vector of weights associated with it. Then, the neuron puts this sum through a predefined function that maps from one scalar value to another. We call this function an activation function. The sigmoid function is a typical example. The ANN consists of layers of these artificial neurons. Each neuron takes the outputs of the neurons from the previous layer as an input. The input for the first layer is the input of the ANN. The output from the last layer is the output of the ANN. The weights of all the neurons in an ANN are the parameters of the function in the hypothesis space. In other words, Deep learning uses a particular type of function for the hypothesis space. However, the same principles from probabilistic machine learning apply.
Deep learning makes heavy use of the operations of linear algebra. Today, GPUs accelerate these operations.
Artificial Intelligence meets Energy
The field of AI has primarily focused on improving accuracy. While AI still makes mistakes, it has surpassed human abilities in many fields. For example, in 2021, AI surpassed human accuracy in answering visual questions and understanding English. In 2016, AI beat humans in Go, one of the most complex board games.
Nowadays, we only see marginal improvements in accuracy, and energy consumption has skyrocketed. The chair has extracted three pivotal observations from Stanford University's 2023 Artificial Intelligence Index Report that support these claims.
Performance Saturation
Firstly, there's a noticeable trend of Performance Saturation within AI. This means that despite our efforts to make AI more accurate, it's not improving as rapidly as it used to. In most tasks, performance gains are now only in the single digits. In the past, we would see big improvements every year, but now they are much smaller. For instance, last year, AI only got about 4% better on average, compared to a historical average of around 42.4%. So, the pace of improvement in AI is slowing down, and the gains we're making are relatively modest.
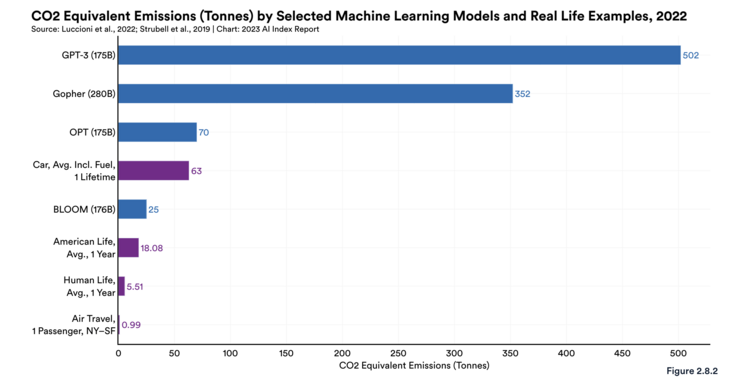
Scaling and Costs of AI Models