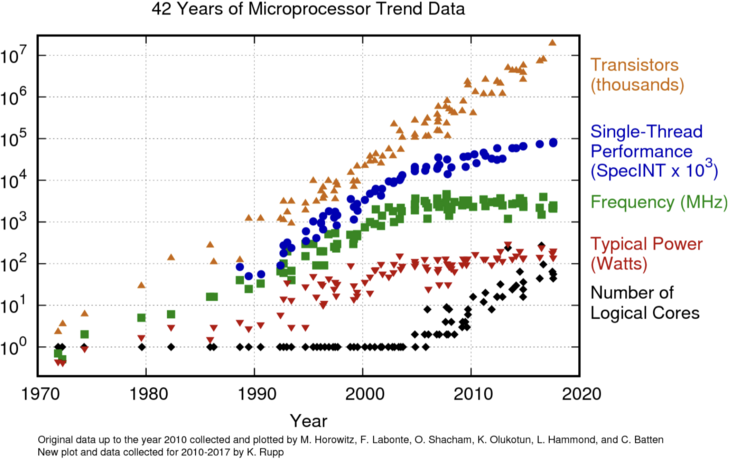
Figure 1: The historical trend in microprocessor development: Until the mid-2000s, the frequency of a single core increased steadily. Afterward, the number of cores increased, while the frequency remained constant [2].
GPU Accelerated Data Processing
To meet the increasing demands on data processing systems, specialized hardware such as GPUs (Graphics Processing Units) can be utilized. A GPU is a specialized coprocessing chip, an accelerator for specific types of operations, originally built for rendering images.
A key feature of GPUs is their significantly higher number of cores compared to CPUs, enabling them to perform a vastly greater number of computing operations simultaneously. Modern GPUs can process up to 3 terabytes (TB) of data per second, whereas conventional CPUs typically achieve data processing speeds of around 100 gigabytes (GB) per second [2]. In the context of data processing, the quantity of data often exceeds the capacity of the GPU's onboard memory, necessitating the supply of data from external sources.
In traditional computer architectures, the GPU is connected to the CPU as a coprocessor via the PCIe (Peripheral Component Interconnect Express) interface, which is then connected to the system memory. The maximum data transfer rate of PCIe is only 32 GB per second [2], a fraction of the GPU's data processing capability. Therefore, the connection between the GPU and the system memory becomes a significant bottleneck, limiting the overall performance of data processing systems [3].
GPU Interconnect
To prevent the data connection from becoming a bottleneck [7], GPU manufacturers have developed specialized bridges, such as NVLink 4.0, which significantly enhance data transfer rates between GPUs and between GPUs and CPUs, supporting transfer speeds of up to 900 GB per second [2, 4, 5]. This advanced interconnect technology reduces latency and increases bandwidth for data-intensive applications, ensuring that GPUs can operate at their full potential without being hindered by slow data transfers.
To fully utilize the system's maximum capacity, a comprehensive understanding of individual hardware components and the overall hardware topology is essential. This includes knowledge of how the GPUs, CPUs, memory, and interconnects are arranged and how they communicate with each other. A well-designed hardware topology can minimize data transfer bottlenecks and maximize computational efficiency, allowing for optimal performance in tasks such as machine learning, scientific simulations, and large-scale data processing.
Scalable GPU-based Join
One research topic from Professor Rabl's group focuses on leveraging the advanced processing capabilities of GPUs and improved interconnects, such as NVLink, for efficient data management of arbitrary data volumes. One of the most crucial operations in data management for relational databases is the join operation, which combines tables of data based on a shared key.
Traditionally, this join operation can be performed through a nested loop, where for each key in the first table, a search is conducted across the entirety of the second table for corresponding keys. This method, while straightforward, is computationally expensive and time-consuming, especially as the size of the tables increases. A more efficient approach is the hash join operation, which constructs a hash table from the keys of one table. The keys of the second table are then hashed and matched against this hash table, allowing for faster lookup and matching [6].
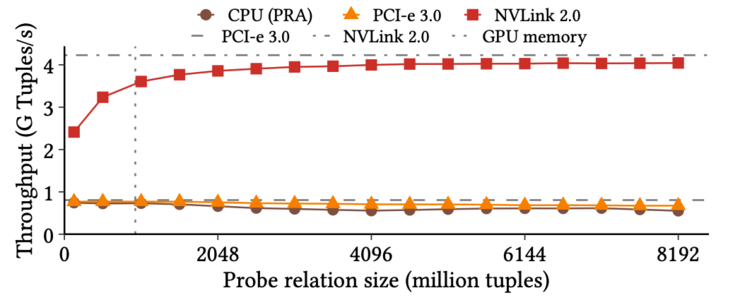
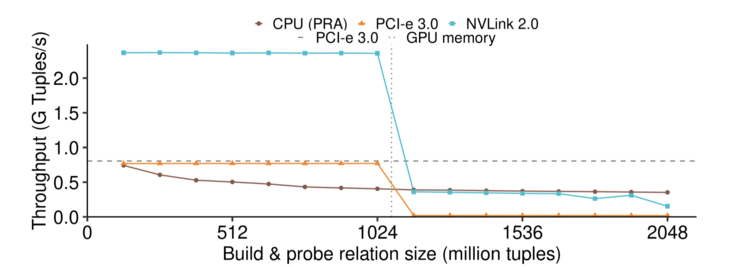
For the primary tasks within the hash join operation—namely the construction of the hash table and probing for matches—it is possible to leverage the parallel processing power of GPUs. When using the GPU for probing, the hash table is first loaded into the GPU's memory. The data to be matched, residing in the CPU memory, is transferred to the GPU using high-speed interconnects like NVLink. This setup allows the GPU to hash the incoming data and check for matches against the hash table in parallel. The parallel nature of GPUs significantly accelerates this process, making it much faster than performing the same task on a CPU, as illustrated in Figure 2. The increased speed and efficiency are particularly beneficial for large-scale data processing tasks.