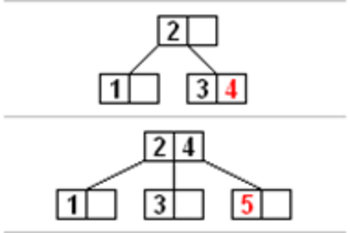
A summary by Mona Sobhani.
Fifty years ago, Rudolf Bayer and Edward M. McCreight, both working at the Boeing Research Labs, invented a data structure called “B-trees” that is nowadays one of the most used data structures in database systems. It has changed the way of storing data and thereby enormously reduced the IO-costs for searching, deleting and inserting data in a database. This blog post aims to show how the structure of the B-tree is organized, how an algorithm on this structure works and how this data structure has evolved since the invention in 1971, when they published it in a scientific paper which is called “Organization and Maintenance of Large Ordered Indices”.
Structure and characteristics of the B-tree
Before inventing the structure of a B-tree, data was organized with index tables. The more data, the longer the index table got or even became a two-level index. Indexing helped to find data faster. For example, if you are searching for specific data, you would use the index to see what block of data you would have to access (load into memory), to find the data. This allows you to not access all the blocks on the disk but just one block, where you will find the data you are looking for.
If the index table is getting too large, one can use a two-level index where the first index points to another index in the second level. One can even use more than a two-level index. When there are too many levels, a B-tree comes into hand. Having a lot of data, or in this case many primary keys, a B-tree organizes the keys in the nodes of a balanced tree.
Each node consists of an index-key and a pointer to the data block, where the data can be found. If we use the same example as before, how do you we now access the data? Looking for a specific key, we now do a search similarly to a binary search. Start at the root of the key and continue either at the left child node or right child node depending on the key number. The B-tree is balanced and therefore assures us to find every key in O(log n). But before looking at the efficiency of a B-tree, we will have a look at the structure and the conditions of a B-tree.
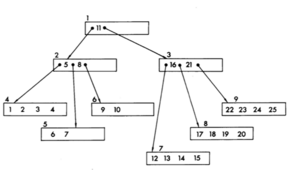
The following figure should help to understand the structure of the B-tree, which Bayer and McCreight published in their paper.