Rompf emphasizes that in order to develop efficient Data Engineering Systems many different branches in IT research need to be combined. In his talk in the Lecture Series on Practical Data Engineering at HPI, he focuses on the role of programming languages and compilers in the development of these systems.
He begins by introducing research results of his early research career. The first presented result [1] is a technique to achieve asynchronous program behaviour while maintaining an easy to follow synchronous code syntax. It utilizes the type system of programming languages. An implemented ‘sleep’ function for example can be tracked in the type system. Using an effect annotation, the ‘sleep’ primitive can be used to work in an asynchronous way. This technique, called delimited control operators, can be seen as a way to mitigate the dreaded ‘callback-hell’ often seen in complex asynchronous code.
The second result [2] again uses the type system. This time the goal is to have high-level code be executed as efficiently as optimized low-level code. By overloading operations using a marker type constructor in the type system, efficient execution could be enabled while maintaining a higher level of abstraction. E.g. operations on a floating point variable could be implemented such that they construct a computational graph that enables fast execution.
Multi-Stage Programming for straight-forward development of Query Engines
Following the introduction of these research results, Rompf focuses on the concept of Query Engines. He initially addresses the usual procedure of transforming a Query Language input into a Logical and then a Physical Execution Plan. Rompf states that these steps are similar to what a standard compiler does when compiling source code. The only difference is that Query Engines do not generate native code in the end. Disk access bottlenecks in earlier stages of database research made this optimization unnecessary. With the abundance of main memory nowadays however, the translation into native code becomes more relevant.
As a milestone, Rompf mentions a paper that proposes using LLVM, a modular compiler framework, to compile queries in order to enhance performance [3]. This however is still a low-level approach. The second milestone was a paper published in 2016 in which various intermediate languages were used to implement the generation of native code [4]. Given a translation between these languages this may result in efficient low-level code. The problem here is that those languages and translations need to be defined and their correctness ensured. The paper concludes that ‘creating a query compiler that produces highly optimized code is a formidable challenge.’
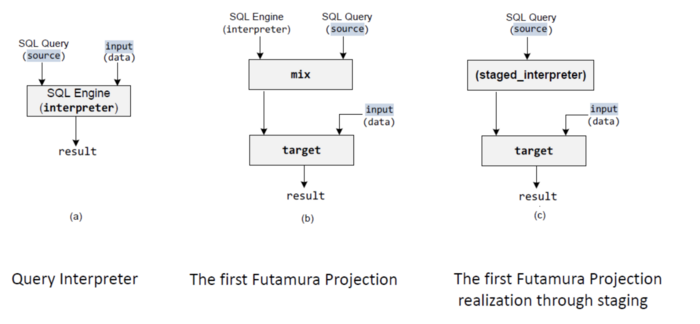
In order to simplify this, Rompf introduces the idea of Futamura-projections that were introduced by Yoshihiko Futamura in 1971 [5]. The key insights of the first Futamura Projection is that compilers and interpreters are not fundamentally different. In fact, an interpreter can be transformed into a compiler through specialization. However the component to automatically generate specialized interpreters (historically called “mix”) is difficult to implement. This problem can be met using an additional level of indirection. The idea of multi-stage-programming (second research result as above), which makes use of the type system, can be a solution to the problem. If custom types are implemented such that they generate specialized code for overloaded operations, this specialized code can be executed without changing the original code. If an interpreter is implemented using these custom types, the resulting ‘staged-interpreter’ can be used to compile code.