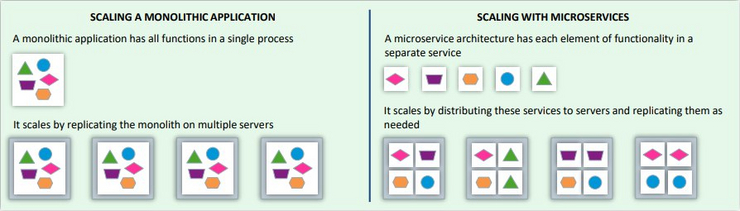
Moving a monolithic AI system from the lab environment to production requires additional steps to take. In production the workload will be higher, thus AI system needs to scale well. The monolithic architecture consists of modules that are hardwired together. In this case, to scale up, you need to replicate the whole system. When one hardwired component fails, you have to shut down the whole instance, adjust it, and turn it on again. To avoid this, in Schufa, they use microservice- based architectures, in which every component is defined as a microservice and communicates with the others. Thanks to this approach, components can be scaled or adjusted separately from the entire instance. For example, if you need more bin-hashing components in your AI system, you scale up only the microservice responsible for bin-hashing, without the need of touching any of the other components. This allows for a lot of flexibility and is a must-do when migrating AI systems to production.
Furthermore, Schufa, as a credit bureau, needs to do a lot of monitoring, quality assurance, logging, just to satisfy all the German and European law regulations. Hence, their system not only needs to be working but also needs to conduct all the mandatory tasks related to a credit information provider in Germany. It gives a conclusion that from a lab environment to a production environment there is a very long way for an AI system to go through.
Schufa developed a specialized prototyping platform for helping them to choose the finest machine learning algorithm for a particular process. The platform is called ScoreStudio. It works similar to AutoML, which runs several machine learning algorithms and tries to find the best predictive model possible for the data provided. ScoreStudio is lightweight (can work on a laptop), is implemented in c++, and specifically designed to work with Schufa processes (e.g. fraud prediction). You only need to point where your data is and it will do the rest, for example, the indexing of the data, or preprocessing of the features. It can provide a solution for 15 million data points in around 16 minutes and come up with several best predictive models (e.g. random forests). ScoreStudio has all kinds of statistical analysis, like accuracy, precision, recall, or F1. All this gives an idea of what kinds of models will work best for a particular process and the data. It is not 100% accurate in predicting the best model but can give a hint about what models to choose from to use in production.
Predictive Models (That We Can Understand)
Even though self-learning systems already yield impressive results and oftentimes surpass humans in classification tasks, the Schufa decided to keep humans involved in most decision making processes. The company depends heavily on the trust of its customers, which is based upon qualities that computers yet need to learn. Being transparent about their reasoning is one of them. Trained decision-making systems – other than humans – oftentimes lack the feature to explain why they arrived at a particular conclusion.
The complexity of deep-learning methods makes factorization of the end-result oftentimes infeasible. Political or religious biases that the machine may extract from training-data are usually not appreciated by the designers of the systems, but hard to come upon. Especially when trained on live-data excluding biased or faulty data is a major challenge and makes the system vulnerable to manipulation. Even data that is fully objective might infringe on cultural and moral conventions that are simply unknown to the computer.
Another issue arises from prescriptive inquiries. If the computer has problems reasoning about its output, how then should it help the human understand what he can do better? In the case of Schufa, customers tend to request clarification over what they can do to improve their situation or what they should rather avoid not to harm their current profile. Some countries even require their credit institutions to explain themselves to the customer when denying a loan.
The classical approach in the credit business sector is to use decision trees combined with logistic regression for the tree’s leaves. These two methods allowed to separate data points in the model into classes by some predicate. This predicate made it feasible to reason about some classification and allowed humans to review a decision later on. Despite this benefit in reasoning, separating data points into well-defined classes is ends up being a limitation in many applications.
To overcome this limitation, Kasneci and his team recently published an approach that employs another split criterion for the node models. His approach made classes separable, instead of separating them immediately. His model also yields results at a tree depth of 1 that compares in quality to separation-results of a tree depth of 3 when following the old approach.
Another new technique that allows for instance-based explainability relies on Deep Neural Networks. Kasneci’s approach computes a gradient at each node of the neural network, aggregates those gradients in a forward manner to then form a linear model in the input variables for some given point. This LICON-termed method allows to find features with strong influence, and also the direction of their influences. Applying this to the MNIST dataset for numbers, the outcome allowed the inspector to reconstruct why samples were classified the way they were.