Big data is all around and data science has become a very interesting topic in the society and industry. A study from 2016 (CrowdFlower’s Data Science Report) discovered that data scientists spend 80% of their time with data preparation.
A data preparation pipeline consists of profiling, extraction, transformation, matching, discovery and cleaning. In the lecture Prof. Dr. Ziawasch Abedjan focused on data cleaning.
1 Error detection
Before detecting and correcting data errors one have to answer the question what data errors are?. Basically it can be anything that a user does not want to have in the data set. Common types of errors are missing values, uniqueness errors like the same id in two different entries, representation errors like another order of first name and last name, contradictions for example between age and date of birth, typos, incorrect values or column shifts.
In the following we summarize the presented error detection algorithms.
Rule Violation Detector
Rules can be defined as functional dependencies for the data set. For example the same zip code should always lead to the same city name. It can be considered an error value which violates this rule as an error. Later we will see that one can also use these rules to find corrections.
Pattern Violation Detector
This algorithm uses more fine granular rules, so-called patterns. For example one could define a format with a regular expression for every column. Anything that violates a pattern can be considered an error.
But note that when a value breaks a rule or a pattern, it is still not known what is exactly wrong with it.
Outlier Detection
Furthermore there are statistical approaches such as Outlier Detection. It uses heuristics to identify what can be an error. So a value that does not fit in the distribution can be considered an error. But not every outlier is a data error. An outlier is only a heuristic for us to figure out if something was an error or not.
Knowledge Base Violation Detector
This algorithm validates the data set with a master data set with mostly clean values.
Now one can ask, which type of detection strategy is most effective to find errors. In 2016 Prof. Dr. Ziawasch Abedjan and his group did a study to answer this question. They discovered that data sets rarely contain only one issue and there is a mix of different problems. Therefore there is not a single best strategy but we need all of them. They also found out that there are not only a few errors in a data set but thousands so automation is really needed to find errors.
1.1 Possible directions for aggregating error detection algorithms
There are different directions to aggregate the results of multiple error detection algorithms. They can be divided into unsupervised methods and semi-supervised methods.
When looking at unsupervised methods one can do majority voting, union the results or do a minimum agreement, so at least k strategies have to agree that a value is an error. Between agreement and union there is always a precision and recall tradeoff: The more tools agree that the value is an error, the more precise the result will be, but the fewer errors it will discover and vice versa.
With semi-supervised methods it is possible to learn the best combination of error detection techniques and transfer error detection into a classification task.
1.2 Implementation
The groups idea was to holistically combine multiple error detection strategies and predict each value of the tuple t[i] as clean: 0 or error: 1. More detailed, they have multiple error detection strategies for different systems and each system outputs a value for each data cell on our data set. So they get multiple binary matrices and for each tuple value exists a string of zeros and ones.
Additionally to make this more compelling Prof. Dr. Ziawasch Abedjan and his group enriched the feature vector with additional simple heuristics which can be generated from metadata which represents characteristics of the data set.
For that he presented the following five metadata categories.
Data Completeness
Data Type Affiliation
Attribute Domains
Frequent Values
Multi-Column Dependencies
So in their overall system the research group combines these ideas: First they generate the needed metadata for an input data set. Then they run multiple error detection strategies and generate binary matrices. After that they put the generated data in a feature vector. Now they can do ensemble learning and get one final output.
1.3 Evaluation Methodology
In order to evaluate their system the group used the precision, the recall and the F-Measure, resulting from these metrics. The precision being the proportion of errors found that are actual errors and the recall the percentage of actual errors found.
They then compare the resulting F-Measure with measures from popular error detection algorithms. This comparison shows that the stacking approach performs better then the common approaches especially on detecting errors in an address dataset and similar or better on a hospital dataset. Including metadata with the stacking approach improves the results even further. However their approach needs labeled data which is not represented in the evaluation.
1.4 Generalizing labels
Overall, generalization in error detection is difficult. Since a generalization would have to capture not only the syntactic but also the semantic aspects of a label. It is possible that there is just a typo in one of the labels or that a label is entirely wrong. However many of these aspects are covered by different existing techniques. These need to have the right configuration to capture certain aspects of errors. In order to automatically generalize labels Prof. Dr. Ziawasch Abedjan and his group developed the Raha System.
1.5 Raha System: Automatic Algorithm Configuration
Instead of manually finding the best configuration for each algorithm, Raha generates a wide range of configurations for each of the used algorithms. This results in a large amount of error detection strategies that capture the similarity of errors.
The output of these different strategies is then used to generate feature vectors for each label. According to these feature vectors the labels are then clustered. In order to then determine if the labels are good or dirty the user needs to label these clusters. To maximize the knowledge gained from each labeled value and since cluster are separated amongst the columns of the feature, vectors tuples are chosen in a way so that they cover as many as possible unlabeled clusters. This is done till the user hits his label budget.
Afterwards training and classification can be done.
For comparing Raha to current approaches an experimental setup was used with eight different datasets and different algorithms that were compared on precision, recall, the F1-measure and runtime.
Results of these experiments showed that with only 10 labeled tuples Raha already outperforms all compared approaches. This gap widens as the number of labeled tuples increases.
Since running each algorithm with each configuration is rather expensive the group used meta-learning. Old data was used to filter out configurations that performed poorly in the past in order to not waste time executing these strategies.
Results showed that using this approach reduced the runtime by a big margin while only reducing the effectiveness by a small amount.
The limitations of the approach Raha takes are:
It does not handle errors done by the user while labeling the clusters
It does not provide enough context for the user while labeling
It does not correct found errors
There is no guarantee how good it actually works
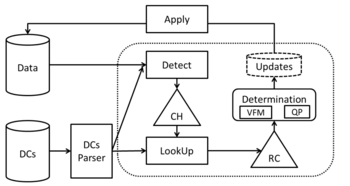
2 Error correction
Prof. Dr. Ziawasch Abedjan went a step further in his studies on how to clean data. As a second part after discovering the errors within the data set, there must be a mechanism to fix the corrupted tuples, for which two somewhat different approaches were presented. The first, developed at the University of Waterloo, Canada, has been an approach which uses denial constraints, whereas the second method uses a statistical background knowledge to repair the data set.