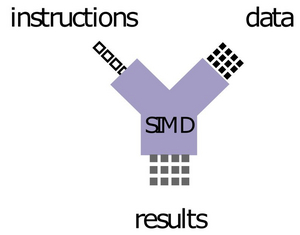
Apart from parallelizing instructions, it is also possible to parallelize data. This means that one instruction process multiple data units at the same time. Figure 2 shows the conceptional idea, the single instruction multiple data (SIMD) technique. For each instruction, a multiple of the data is loaded. Since this highly depends on the type of instruction and data, modern CPUs provide only the hardware. The usage and management have to be done by the application or operating system. Still, it counts as an implicit parallelization technique because the parallelization that happens leverages hardware-specific features and is executed on a single core.
How exactly can we exploit these techniques for database systems?
In the following we will focus on transaction processing systems. In a 4-way issues Intel processor you can theoretically execute 4 instructions per cycle, but for most applications it is typically not much more than one instruction per cycle, so there is a lot of room for improvement. The reason for the low number of instructions per cycle is the high stall time, the time in which no instruction can be processed because the memory has to be accessed for instructions or data. This behavior does not only occur with Shore-MT transaction processing systems. Also commercial systems and in-memory systems that have a newer code base spend a large part of their time in stall cycles. These systems can be very good and have a high throughput, but you could get even more out of them by using the hardware as best as possible.
This problem can be solved by looking at how the stall cycles are used. In most cases, they are referring to instruction-related memory accesses. If you then take a closer look at these memory accesses, you will see that most instances of a transaction generally access the same instructions, but almost never the same data. Even with different transactions, this phenomenon occurs because transactions are made up of different atomic components that use the same instructions.
You can take advantage of the fact that instances of the same transaction have a lot of instructions in common by processing the transactions in such a way that the instructions in the L1 instruction cache do not need to be reloaded each time. So we can break our transactions down into such small pieces that all instructions fit into the L1 cache. If more than one transaction is to be processed, the first part of the transaction is executed on one core and then switched to another core on which the second part of the transaction is executed, the instructions for the execution of the first part of the transaction are kept in the L1 cache of the first core and can be used by the second transaction to immediately start executing its first part. You can also load the instructions needed for the next part into the L1 cache of another core to avoid the downtime for waiting for instructions to be fetched. So you save yourself having to get the instructions each part needs, since you already have them in the cache. As a result, the cache needs to be filled less often and there is less downtime to retrieve instructions.
However, there are also negative sides to this approach, the first transaction has to load each of its instructions because there was no transaction before it that already cached the instructions, and in addition it has to bear the cost of transferring them to another core. So if a short latency is more important than high throughput, this method is not recommended. Furthermore, it must also be taken into account that when migrating to another core, the data must also be reloaded. Loading the data when migrating to a new core on the same socket is not as time-consuming as reloading the instructions. However, if you want to migrate to a new socket, this step is more important and the entire process is no longer significantly faster.
So as long as we only have more cores on a socket, we get an almost ideal ratio of throughput to the number of threads with the method described, but as soon as we start using several processors on different sockets, as is often the case in newer systems, the bad effect of the access times on the data comes into play and worsens the ratio. So it is important that we get better metrics to decide on scalability, because the pure throughput that is possible on paper does not necessarily say anything about whether future systems scale as well as today's systems do.
When looking deeper into the cause of this effect, a critical section analysis is the next step to take. A critical section is section of the code, that accesses shared parts of the data. Due to not causing conflicts, this part of the code can only be executed by one thread. There are several strategies to tackle the critical section problem, which are described in the following paragraphs.
The first scenario are unbounded critical sections. This occurs when shared data access happens. Every thread try to access the critical sections simultaneously. That leads to the problem of increased critical sections access when the system is scaled up - the number of processors or cores is increased - as all running threads could try to access the critical section at the same point in time.
The next scenario are cooperative critical sections. In this case, work of different threads is aggregated. The aggregated instructions, which could be a commit in a database, are all done together at a later point in time. This way of coping with critical sections leads to less unstructured threads that want to access the critical section at a point of time. Its upside is the increase in parallelisation, as lots of different instructions can be handled at a point of time. One disadvantage is the difficulty of managing the access of the critical section and the aggregation. One example, where this is used are group commits.
The last presented scenario are fixed critical sections. For those, there is a given, fixed order for accessing the critical section. It is the same scenario as the producer consumer problem and here is no parallelism involved. The goal is, to reduce the number of unbounded critical sections by transforming those into cooperative and fixed ones. When looking at shared everything database management systems, there are two things, that can be accessed by threads where critical sections can happen. The shared system state, monitoring proper execution of transactions and commits, and the shared data space. If the data space is not managed properly, there can happen a lot of unpredicted database access.
To show the number of critical sections, in a test scenario a probe customer is selected and their balance updated. This leads to more than 70 critical sections, out of which more than 75% are unbounded. To minimize those, physiological partitioning (PLP) can be used. In this case, worker threads have specific data ranges, which will be accessed by those. Also the index structures is mapped to subindexes to grant a fast access of data.
This method is limited by the structure of the saved data. The data has to be separable to decide on which thread is responsible for which data ranges. For example, Names could be split alphabetically by its first letter. Deciding on the separation points is not easy and highly depends on the data. For that, a good knowledge of the given data is required. Sections of data could also be assigned to a number of threads, which makes some critical sections possible.
By using PLP, the number of critical sections can be reduced by 70%. But PLP does not help on a multicore with several processors. In such servers, as the remaining unbounded critical sections are based on lock-free or atomic mechanisms.
Having reduced the number of critical sections does not solve all of the problems, as sharing data among cores on different processors also leads to high latency. It is 10 times as high as accessing another core in the same processor.
A question for further research is the possibility of adding heterogeneity. Adding more and more cores in one processor does not work, as those cannot be powered all at the same time. One possible solution for this problem is to use many light cores. Those could, in the end, consume more power when running for long hours instead of having high performance processors running a short period of time. An alternative is using diverse cores. That is a better long term solution, as specific processors can take over the tasks, which they are best at.
Problems, that arise when using diverse cores, is the proper exploitation of the cores. Scheduling becomes a problem and also complex energy management is not easy and currently a challenge for further research. As a summary, you can see that hardware parallelism is a complex topic, which needs to be considered when thinking about data-intensive work. Even though hardware is getting faster every year, this does not help tackle the massive amount of data, that is processed. It is widely known, that there are several possibilities to handle parallelism and for writing software, most people were ignorant and relied on the performance increase when developing new data processing algorithms. Putting more and more processors and cores in one system increases the amount of explicit parallelism, that could slow down the system when scaling up the hardware. When thinking about data processing, due to the increasing amount of data, server farms are scaled up to increase calculation speed. As described in the article, this is not always the case and could lead to problems when not thinking about the underlying software. When designing systems, one should always be aware of hardware parallelism and the effects, which could result from that.
References:
Ailamaki, Anastasia / Erietta Liarou / Pinar Tözün / Danica Porobic / Iraklis Psaroudakis (2017).Databases on Modern Hardware: How to Stop Underutilization and Love Multicores Synthesis Lectures on Data Management.Morgan & Claypool Publishers