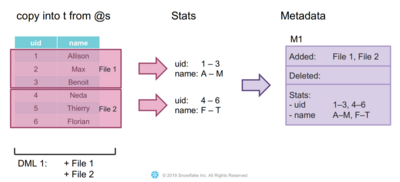
When inserting new entries into an existing table, it is essential to remember that files are unchangeable. This means that the new values cannot simply be added to the existing files. Instead, a new file must be created that contains the new values and expands the table in this way. Also, a new metadata snippet is added that records the added file and statistics about the data in this new file, such as minimal-maximal-value-ranges of each column.
If an entry in a table must be deleted, again, the file containing this entry cannot be changed directly. Alternatively, this file is replaced by a new one. To do this, all entries of the old file, except the one to be deleted, are copied to the new file. A new metadata snippet marks the old file as deleted, while the new one is added. Some statistics about the entries of the new file are also written to the metadata snippet.
With each new DML, a new metadata section is added, documenting which actions were performed by the DML and which new statistics apply. How this metadata management enables increased query performance will be explained in the following.
Select, Pruning, Time Travel and Cloning
Snowflake provides basic functionalities of query-based languages like select as well as special operations like time travel and zero-copy cloning. For all those operations, it uses metadata information to reduce the number of files to be queried. As a result, fewer files need to be loaded from cloud storage and scanned, which significantly improves query performance.
If a user queries a table so that the query could look like “SELECT * FROM table t”, the query optimizer first computes a scan set. This is the reduced set of files that is actually relevant for calculating the search result. Using the t table from the previous chapter, the scan set of the above query would include all files that are marked as added but not deleted in the metadata snippets, namely File 1, File 3, and File 4. Since the query does not contain a WHERE clause, there is nothing else to do except to send the scan set together with the query plan to the execution level to process it.
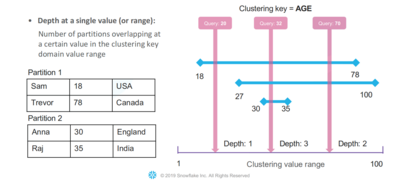
If a query has a pruning predicate, such as the query “SELECT * FROM table t WHERE user ID = 5”, the same scan set as described above is generated in the first step. The statistics of each file contained in the metadata snippets are then used to reduce the scan set further. As mentioned in the previous chapter, these statistics include the range of values for each column of a file. With this knowledge, Snowflake can easily compare the pruning predicate, user ID = 5, with these ranges. This way, it is possible to determine the file that actually contains the desired value; here, it is File 4. Now only this single file has to be processed in the execution layer, which is much faster than scanning all files of the original scan set.
Another function is time travel. Since the metadata sections can also contain timestamps, users can select files that existed at a specific time. This means that if a file is deleted at 3 pm and a user then asks for all the files that existed at 2 pm, he will also receive the deleted file. This is only possible because Snowflake never physically deletes a file, but only marks it as deleted. A corresponding query could look like “SELECT * FROM table t at (timestamp =>'2pm')”. In detail, the scan set is reduced to the state of the given timestamp before either an additional pruning predicate is executed or the query is sent to the execution level. For Snowflake users, this function is limited to 24 hours by default, allowing users to revoke any modifications made in this timeframe.
The zero-copy clone is a feature that extends the SQL standard to enable table cloning in a memory-saving and performant manner. Here, no real data is cloned in the cloud, only the metadata of the files. Hence the term zero-copy. An example would be the query “Create table t2 clone table t”. To perform such an operation, all metadata snippets of the source table t are combined in a new metadata snippet. This metadata is then assigned to the new table t2 and will be the basis for all future queries on this table. In combination with the time travel function, this technique allows the user to create a zero-copy clone of a table with its contents at a specific time. This can be useful for backup or testing purposes.
To improve the query runtime when pruning, Snowflake has implemented automatic clustering.
Automatic Clustering
While the first part of the talk explains how Snowflake stores data and manages metadata, the second part is about its automatic clustering approach.
Clustering is a vital function in Snowflake because pruning performance and impact depend on the organization of data.
Naturally, the data layout (“clustering”) follows the insertion order of the executed DML operations. This order allows excellent pruning performance when filtering by attributes like date or unique identifiers if they correlate to time. But if queries filter by other attributes, by which the table is not sorted, pruning performance is unfortunate. The system would have to read every file of the affected table, leading to poor query performance.
Therefore, Snowflake re-clusters these tables. The customer is asked to provide a key or an expression that they want to use to filter their data. If this is an attribute that does not follow the insertion order, Snowflake will re-organize the table in its backend based on the given key. This process can either be triggered manually or scheduled as a background service.
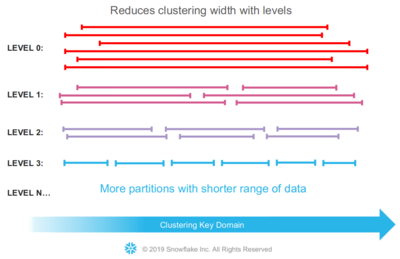
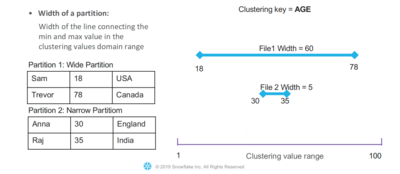
The overall goal of Snowflakes clustering is not to achieve a perfect order, but to create partitions that have small value ranges. Based on the resulting order of minimal-maximal-value-ranges, the approach aims to achieve high pruning performance.
This is illustrated using the example of a table perfectly ordered by an identifier column. Each partition has a range of ten values, while the total range goes from 1 to 100. If new data is added by the customer using DML operations with a range from 1 to 100, the newly inserted data affects every single file of that table. Every partition would have to be rebuild, leading to performance issues.
To keep up with DMLs, Snowflake has evaluated several approaches. One of them is re-clustering inline with the changes, meaning that all loads would be on the DML operations. Unfortunately, this increases the effort of DMLs, decreasing customer performance.
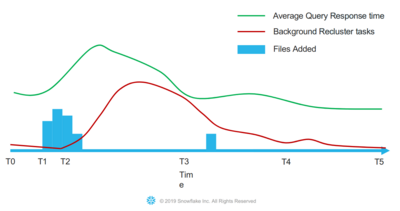
Another approach is batch re-clustering, in which a periodically triggered job would rebuild the table. This solution would be slightly better as DMLs are still fast, but the tables would be locked during the re-clustering process. For tables in Snowflake, which are up to petabyte sized, this would cost too much time to be applicable in practice. Also, the query performance degrades until then next clustering process starts.
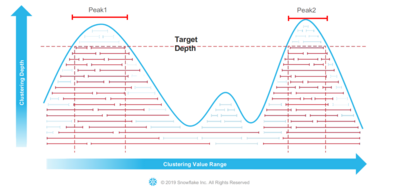
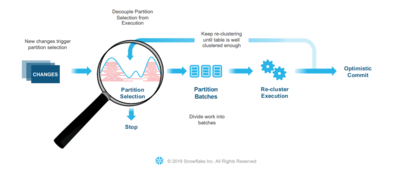
Hence, Snowflake decided to use incrementally re-clustering in a background task. Periodically, a small set of candidate files is re-organized to maintain an optimal performing table layout. This process repeats until query performance is at a satisfying level. Again, Snowflake does not aim for a perfect re-clustering but a balance between locking parts of the table and good clustering results.
To understand automatic incremental re-clustering, the basic functionality of Snowflake’s algorithm is explained. Data insertions trigger a process that uses metadata information to identify the files that need to be re-clustered to maintain query performance. In doing so, the system builds batches for re-clustering. Those will be re-sorted based on the correct clustering order given by the customer. Using an optimistic commit approach avoids locking the table during that process.