Users
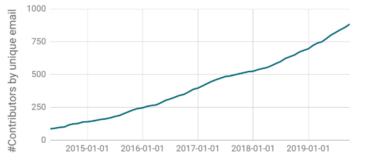
Apache Flink is used by many well-known companies, including but not limited to eBay, Yelp, Uber, Comcast, and Alibaba. Alibaba recognized the benefits of Apache Flink to such an extent that they have recently acquired Ververica to intensify their commitment to stream data processing and pushing the development even further. [8] Arvid also pointed out that most of these companies use Apache Flink for real-time event processing and they still use Apache Spark for batch processing.
Use Cases
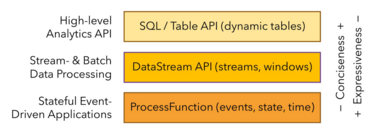
Use Case: Event-Driven Applications
Event-driven applications ingest events from one or more streams and react to incoming events by triggering computations, state updates, or external actions. Traditionally these kinds of jobs are separated into different computational and storage tiers where the application reads and persists data to a remote database. Event-driven applications, such as Flink, improve this concept by co-locating the state near the application. Persistent memory is only used for fault recovery, which improves application speed in terms of throughput and latency. [9]
Use Case: Batch & Stream Analytics
Analytical tasks pursue the goal of generating insights from raw data. Traditionally, such tasks are performed in batch queries on limited datasets of recorded events. To include new data in the analysis, the entire analysis process must be repeated on the new data set. For this reason, continuous analysis with streaming analytics has evolved. Events are processed in real-time and the resulting state can be used by other applications, like a monitoring dashboard. Apache Flink supports both query types by providing an interface with unified semantics for batch and streaming queries.
Use Case: ETL and Data Pipelining
It is common for data to be converted and moved between storage systems. For this case extract-transform-load (ETL) systems are built, which are periodically triggered by an external tool. For this purpose, Flink provides compact and easy-to-implement data pipelines. They fulfill the same task, but process the data continuously. This makes the results visible quicker and the pipelines can be used in a more versatile way.
Stream Processing
A Flink program comprises streams and transformations. A stream is conceptually a (potentially endless) flow of data. In this context, a transformation is a process that takes one or more streams as input and generates as a result one or more output streams. During execution, a Flink program is mapped to a streaming dataflow. A streaming dataflow consists of one or multiple sources (input), a computation/operation as well as one or more sinks (output) at the end. The dataflows are similar to arbitrarily directed acyclic graphs (DAGs), which can be executed in parallel. [10]
State Management using Checkpoints
Many of the operations used in stream processing are stateful, since the steaming data arrives over time whereas of course not all data can be kept. Therefore, operations must remember records or temporary results. In order not to loose the state of a variable in case of failure, Flink maintains the state locally per task (in-memory or on-disk) using periodic, asynchronous incremental snapshots. In this case, a checkpoint represents a consistent snapshot of the state of all tasks. This is achieved by all tasks copying their state when they are at the same location of the input (“checkpoint barrier”). With this approach, Flink implements an exactly-once consistency, since in the event of an error, the system continues from the checkpoint and the previously processed data passes through the pipeline again, so that each piece of information is processed exactly once.
In contrast to checkpoints, Flink also offers savepoints, which are intended for planned application upgrades, suspending and resuming applications and migration to upgraded infrastructure, as they are much more extensive and take longer to create and to import back into Flink. [11]
Differentiation between Event-Time and Processing-Time
Depending on the application and its purpose, there are differences between event-time and processing-time. Processing-time refers to the time stamp at which a record arrives, which can lead to non-deterministic results, since records might be out of order. The processing time is also not applicable when having recorded data, but might be useful to approximate low-latency results.
In event-time processing, the records are processed based on an inherent “watermark” with which you can achieve that no record with a timestamp before the watermark is left there to be processed. Results are consequently deterministic since records are processed in the order of creation which therefore requires more time to wait for records that are out of order. The use of event time and processing time depends on the application and its requirements for accuracy concerning the order of processing records.