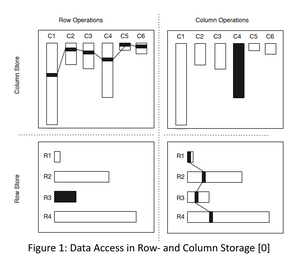
Such online analytical processing (OLAP) workloads greatly benefit from a column-wise layout. It maximizes throughput to the CPU for sequential column element accesses and enables efficient use of hardware caches, compressing techniques and vectorized processing with SIMD instructions. Transactional processing, in turn, is complicated with this data layout, as records have to be inserted at multiple locations. More information about this approach can be found in [0].
Traditionally, multiple database systems running concurrently would, therefore, be dedicated to either OLTP or OLAP, with periodic ETL processes duplicating data into the analytical systems so that transactional systems could run unhindered by analytical queries. HTAP database management systems aim to overcome this redundancy by providing sufficiently fast transactional processing and high-performance analytical processing on the same column-store data structures that are kept in main memory.
Team Setup
The HANA development team is located in six international sites, centering in three main hubs in Canada, Germany, and Korea where in addition to feature development also research is conducted. Roughly 1.100 employees are part of the team.
The key skills of the developers include performance-aware knowledge in C, C++, rarely ASM, and knowledge on modern software development best-practices. Expertise in operating systems, hardware, and advanced topics in database technologies are essential as well.
SAP HANA Development Process
Customers heavily rely on a database as a source of ground truth at the core of every enterprise application. To meet this trust, it must be highly stable and reliable in order to avoid downtime or loss of data. Also, enterprise use mandates other capabilities such as encryption, auditing or backup and recovery. In the case of SAP HANA, performance of the database is also a crucial feature that is used to distinguish it from competing products. Despite these strict requirements, the development team must also be able to react to feature requests to increase usefulness for customers and therefore adoption. To ship updates quickly, new on-premise versions are released yearly and cloud versions in a monthly cadence.
This forces the team to find a careful balance between a high development pace to meet feature pressure and nevertheless delivering a highly stable and regression-free complex DBMS. In the following, we detail the techniques and technologies used to reconcile these counteracting goals:
Tooling and Development Environment
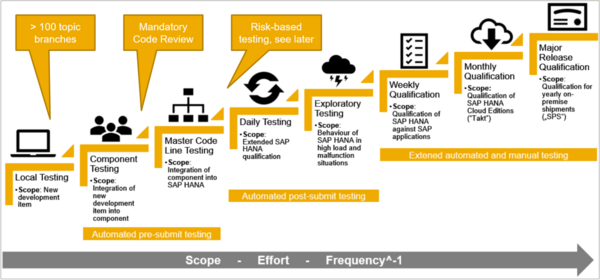
The codebase of the HANA DBMS now encompasses more than 11 million lines of C++ code. Builds are released exclusively for linux-based systems, so that no deviation from commonly used build tools such as CMake and gcc is necessary. For local development, the team members are free to choose a development environment, i.e. they are not dictated to use a certain IDE, git client, etc. and can choose what they are most comfortable with. With git, another industry standard is used for version control. The project management with all tasks is done via JIRA, the bug tracking via Bugzilla and for documentation, a correspondingly large Wiki is used. The team also uses more specific tools especially useful in the context of database development: For testing purposes, Google Test is used, a framework commonly used for C++ projects. Performance benchmarking and regression analysis are conducted with Intel VTune, which can be used to find bottlenecks. Most interestingly, the team utilizes a reverse debugger from Undo. Open-source alternatives include rr by Mozilla. This type of debugging runs an 'observed' execution of the program that records the machine state for every instruction. From a trace file, program execution can be reversed after the fact, which allows the examination of hard-to-reproduce bugs. This is especially useful for complex systems such as databases, where for example concurrency and race conditions can lead to problems.
Processes of Software Development
As a strawman for a traditional mode of development, Dr. Böhm examines the waterfall model. Usually, this model leads to severe problems when requirements for the software change. Its sequential process has different phases that are each accomplished one after the other. The phases are Requirement Analysis, System Design, Implementation, System Testing, System Deployment, and System Maintenance. Problems occur simply because one is unable to change product features during this process. Since the requirements have been designed at the beginning, they can not be changed in another phase which is usually given when feedback about the software is incorporated. Therefore, the waterfall model is very inflexible and unsuitable for SAP's HANA development.
Instead, the concept of continuous integration and delivery (CI/CD) is used. Each developer can integrate code at any time and contribute to the mainline of the code, with automated building and testing ensuring a lower limit of confidence in the software's correctness. Frequent integration of small changes allows the customer to see if the features are what they want in their product. They can test it and provide feedback even before changes are final. An important backbone of the strategy is test-driven development (TDD).
Test-driven development (TDD)
TDD is one of the main ideas to ensure stable and reliable products. Implementation of a feature starts by writing one or more Unit Tests that check the newly required functionality. The developer can then concentrate on writing code until the test passes. This supports quick development as manual checking of functionality is reduced and encourages only adding necessary code. As a major side effect, each feature is at least minimally tested before integrating it into the software. After the test passes, efforts can then shift to refactoring code and improving the implementation.
Tests exist on different levels of granularity, serving different purposes: