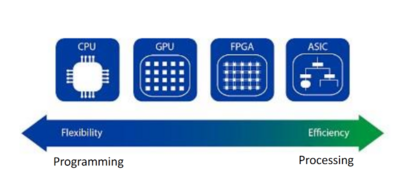
The CPU is very flexible for programmers and optimal for “Serial Programs.” It can be equipped with terabytes of memory and offers simple debugging options. It is not without reason that DBM systems have relied on the CPU since their early days to perform their tasks. New CPU generations usually offer more performance to keep up with increased data volumes - but in recent years, CPUs have become more and more exhausted. The high flexibility comes at a high price when it comes to raw computing capacity.
This is a reason why GPUs have increasingly been used. They can not only process “Serial Programs” but also "Data Parallel Programming" using single instruction, multiple threads ("SIMT") with outstanding performance. Unfortunately, interfaces to other hardware components quickly become bottlenecks. Thus only comparatively limited amounts of RAM can be efficiently connected. The developer’s experience is downgraded because programming and debugging are more complex. So it is not surprising that there are only a few DBMS that truly optimal utilize the GPU even though column-based data would theoretically be suitable for SIMT.
Application-specific integrated circuits are not used despite their outstanding performance as their multi-year and costly development cycles cannot keep up with the fast-moving data processing world. So Swarm64 opted for the remaining alternative: the FPGA.
An FPGA can be programmed to execute any logic but does so "closer to the metal" and, therefore, much faster than CPUs. Although the development is not very comfortable, it is more flexible than ASICs, and updates can be done in a few seconds.
With this approach and a PostgreSQL module called Swarm64 Database Accelerator, which is designed for several FPGA systems, it was possible to create a solution that meets the initial requirements for modern data warehouses. It is significantly cheaper and more straightforward than "scale-out" solutions. Nevertheless, this module addresses some other problems too.
Many so-called data warehouses rely on old and no longer supported DBMS and analysis systems. Other problems are high licensing costs in the millions of dollars per year and having difficulty scaling and integrating new data if outdated data warehouse platforms like Oracle, Netezza, and DB2 are run.
Swarm64 intends to modernize these warehouses through their technology. Furthermore, since they rely on the free, open-source product PostgreSQL as a DBMS and not on proprietary software like many legacy solutions, customers can build on a large community. Many developers and admins are experienced with PostgreSQL as well, which reduces the cost of PostgreSQL further when using the Swarm64 Data Accelerators.
A special case of this deprecated software is IBM's Netezza. In 2003, Netezza revolutionized analytics with its SQL data warehouse appliance. It offered FPGA boards working in parallel to ingest and query large volumes of data warehouse data on PostgreSQL.
Swarm64 offers more than just a simple replacement product. It is faster than Netezza and much more flexible because only single servers in a cluster have to be equipped with FPGAs, while Netezza scales only per quarter. Furthermore, Swarm64 can easily be hosted at large cloud hosters with FPGA support; Netezza only works with a classic appliance model that has to be hosted on own servers.
Another concept Swarm64 is challenging is Time-Series Databases. With the technology and speed that the Swarm64 Database Accelerator can achieve, millions of data changes can be written to a standard PostgreSQL database. So even IoT sensor data can be captured and evaluated in real-time - without the need for specialized Time-Series Databases.
Background: DBMS
Let us take a look at the background of these problems. To refresh: A "database" in the common language consists of two components. On the one hand, the data itself also called a database, and on the other hand, the database management system (DBMS), which manages the data and takes care of querying existing data and inserting new data, as well as corresponding optimizations for both processes. When we talk about a database, we often mean the DBMS. But for what - at a high level of abstraction - do today's software landscape use databases?
They are mainly used for three different purposes. First as a system of record, a system in which data is stored. Since we are talking mostly about important business data, the data thus must be processed quickly, saved, and protected from data loss. On the other hand, we usually want to read individual data records, so we have to search through a lot of irrelevant data to find the right index. In both cases, low latency will count.
Moreover, Databases are essential for systems of analysis, i.e. systems in which a lot of data is read and analyzed. Here we are talking about terabytes of entries that have to be scanned and aggregated. In this case, the bandwidth encounters its limits.
Last but not least, there are the systems of engagement; in other words, those systems where users are encouraged to collaborate, where the data of this system is usually numerous and has a real-time component. Individually the queries are latency dependent, but in aggregate, this is a question of bandwidth.
So if we want to cover all these overlapping use cases, we have to optimize latency and bandwidth. A goal Swarm64 is committed to - how exactly they achieve this goal will be explained later on. However, Swarm64 is also based on a very well-known database: PostgreSQL, an open-source object-relational SQL database, which has been in constant development since the end of the 80s. It is widely used in the developer community and is the fourth most used database worldwide, according to db-engines.com.
Swarm64 decided on PostgreSQL because this free, open-source database offers feature robustness, reliability, and high performance after thirty years of development. Besides this popularity, it was very interesting for Swarm64 because of its easy extensibility. Due to this feature, they could develop their Database Accelerator as an add-on to PostgreSQL without having to modify the code of PostgreSQL itself. So every user of the Swarm64 Data Accelerators can have a "normal" PostgreSQL instance running, which he can configure by further modules or open source modifications as he sees fit. Swarm64 "just" added FPGA acceleration and thereby extended PostgreSQL functionality of analytics.
Background: FPGAs
We have already discussed a vast amount about what can be achieved with FPGAs and why they are better than other hardware accelerators. Nevertheless, what precisely is an FPGA? An FPGA consists of many individual cells arranged in an array. These cells consist of a lookup table (LUT for short - a table that assigns an input to each combination of inputs) and a flip-flop.
Of course, a lookup table - also known as a truth table - can be used to hardcode any logical function. The possible complexity of this function depends on the number of inputs; nowadays, there are mostly 6 of them. These cells are then linked together in a configurable way. That way, very complex functions like the database optimizations of Swarm64 can be programmed into the SRAM of the lookup tables. Hence the name: Field Programmable Gate Array, because they can be reprogrammed in the field and consist of an array of connected logic gates.
The FPGAs for data centers are usually addressed via PCIe, a standard interface with a standard form factor, so that these cards can be installed in almost any server. Of course, this was not always the case, but a result of one of the many trends in the field of FPGAs.
Like many other technologies, FPGAs were initially very expensive, but this changed as manufacturing processes became cheaper, and more manufacturers joined along. The first to use their expensive FPGAs to process large amounts of data was Netezza, which was later acquired by IBM. However, IBM announced in 2018 that it would discontinue this activity. Since then, powerful FPGA cards for enterprise use can be purchased for a few thousand Euros and fit into any server rack. So even smaller companies and startups can optimize their data processing.
Besides, there are significantly improved developer tools that abstract programming and make it easier for classic developers to write software for FPGAs. There are successful efforts by using High-Level Synthesis to automatically convert algorithms written in C into a register transfer language. Therefore, the developer does not have to be experienced in the latter. A rethinking from the "data movement" concept of classical programming to the "data flow" concept of FPGAs is of course still necessary, but also easier to learn. The developer does not have to worry about many pre- and post-processing steps anymore, but can be relieved of the work by libraries.
When a final program is ready to be used on an FPGA, it is easier than ever to roll it out and actually execute it, because many conventional and new cloud hosters provide servers with FPGAs that can be rented per minute if required. However, with FPGAs-as-a-Service the end of development is not yet reached, because FPGAs will also be integrated into other products in the future, such as the Samsung SmartSSD, which will also be supported by Swarm64 and is a combination of SSD and the generally available FPGA. But also, smart network interfaces are now equipped with FPGAs, and this trend will undoubtedly continue.
Approach
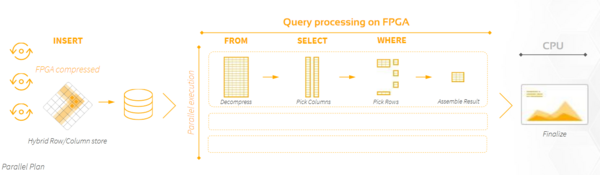
Swarm64 uses different approaches to transform their vision into reality. For one, they concentrated on accelerated tables, which allow handling very large tables and are efficient when using range queries and when data is moving at a high velocity. However, an alternative should be used if the interactions with the table are based on many small transactions, or the goal is to get only single values from an index column.
Another approach is the use of optimized columns to improve data layout. They are best for handling dates, prices, quantities, sensor data, and spatial data and are commonly used for columns that are queried by range. The more optimized columns are used, the faster the query becomes, while the order stays irrelevant. However, the usage is limited to one to three columns per table.
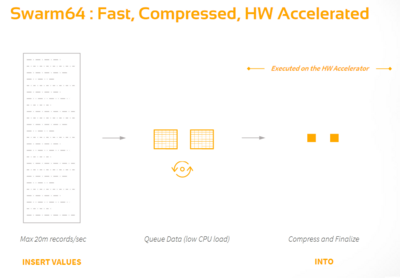
To improve the insertion of records, Swarm64 queues the data in the CPU after insertion and compresses it using the hardware accelerators. Thereby, instead of updating the table and indices in a row store or preparing the data and updating the columns in a column store, Swarm64 is able to achieve 20 million records per second instead of only one million records per second. This approach is illustrated by Fig. 2.