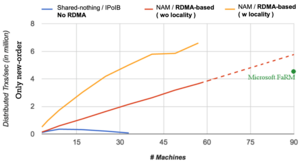
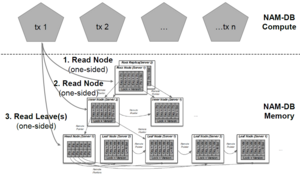
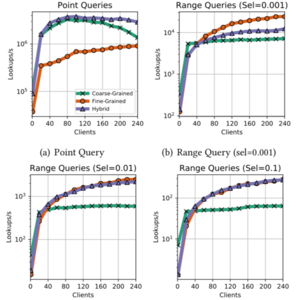
For point queries, the overhead of the fine-grained system lowers its throughput significantly compared to the coarse-grained and hybrid approach. For a higher number of clients, however, the impact of the skewed data access shows. The fine-grained system with its more evenly distributed data is almost unaffected. The throughput of the coarse-grained system, on the other hand, begins to decrease when 80 clients have been exceeded. And while the hybrid system does not increase its throughput anymore, it remains mostly stable and manages to be the highest throughput system for all tested numbers of clients.
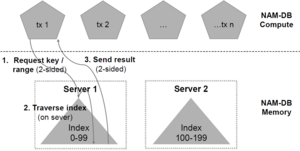
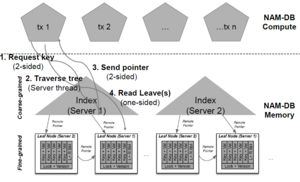
For range queries, the designs behave differently. The coarse-grained system stagnates immediately. Both the fine-grained and hybrid systems appear to have linearly growing throughput with an increasing number of clients. The fine-grained system appears to be faster; however, the difference is only pronounced on queries with low selectivity. Otherwise, the hybrid approach is close to identical to the fine-grained approach.
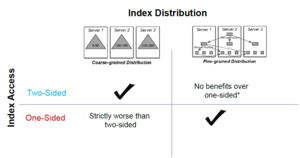
The hybrid approach manages to take advantage of the strengths of the more extreme approaches while mitigating their weaknesses. While it is not the fastest in every regard, it is the most robust across the board and performed well independently of the workload.
Part 5: Conclusion
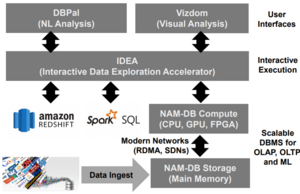
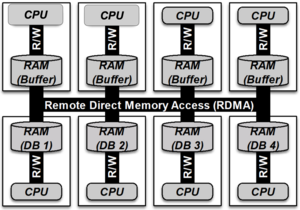
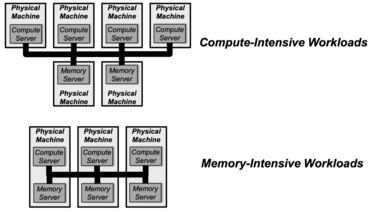
As shown above, database systems can be scaled significantly by connecting multiple servers via a network. The former bottleneck in the network connection can be overcome by using modern high-speed connections and communicating with RDMA to avoid costly overhead. This also enables logical separation of computation and memory so they can be scaled independently. Important memory structures and often accessed data can be distributed over multiple machines. An intelligent indexing structure ensures that the risk of performance losses to contention or load imbalance is kept to a minimum. With all that in place an easily scalable database backend for real-time oriented data analysis systems is possible.
Together with the other discussed components, such as an approximate query enabled middleware and intuitive user interfaces, this facilitates a simple to use real-time data analysis system.
References
[1] Zhicheng Liu, Jeffrey Heer,The Effects of Interactive Latency on Exploratory Visual Analysis, IEEE, p. 2122 - 2131, 2014