Automatic Optimization of Complex Analysis Algorithms for Big Data
Apache Hadoop as a famous implementation of the Map-Reduce framework provides schema-on-read functionalities, flexible handling for user-defined functions as well as scalability that is way better than traditional database systems provide. For instance, Apache Hadoop implements proper mechanisms for fault tolerance and long-running operations to reach targeted scalability. However, a database engineer misses the relational algebra, the declarative programming paradigm, the automatic query optimization as well as the out-of-core robustness.
For that reason, the Stratosphere Project[9] was founded. It aimed to combine the advantages of the worlds of general-purpose programming and database technologies. Besides adding advanced data flows, some concepts of both joined worlds are reconsidered and improved. Apache Hadoop supports batch processing and thereby allows high throughput. However, these (mini-) batching concepts do not minimize latencies. Native streaming functionalities provide low latencies and high throughput. Even though database systems know constructs like recursion, the query optimizers do not deal well with them. Simultaneously, Machine Learning technologies require iterations for its model buildings.
Based on the Stratosphere Project, Apache Flink[10] was born. Apache Flink is officially defined as an “open-source stream processing framework for distributed, high-performing, always-available, and accurate data streaming applications”[11]. Over the last decade, the number of contributors all over the world grew, and various renowned papers[12],[13],[14] describe further improvements. Nevertheless, there are aspects of Apache Flink that are worthy of being illustrated in a bit more detail.
Apache Flink’s Key Concepts For Reducing Human Latency
At first glance, Apache Flink programs strongly resemble programs for database systems due to their declarative structure. Thereby, two models exist, an algebraic model and a cost model. The cost model is used for automatic query optimization. The algebraic model consists of second-order and third-order functions. Apache Hadoop already provides second-order functions, called map and reduce. A map function in Apache Hadoop represents a parallelization pattern that applies a user-defined function on every single record of one single input. Apache Flink refines this concept and implements the cross-function that is defined analogously to Apache Hadoop’s map function but allows multiple input streams. Apache Flink refines the concept of the reduce function equally. In Apache Hadoop, a reduce function represents a parallelization pattern that applies a user-defined function on a group of records of one input. Apache Flink’s refinement, called co-group, allows multiple input streams again. Due to these refinements, developers are able to express join logics without mixing logic for query processing and data analysis, as Apache Hadoop requires it. Thus, Apache Flink code becomes more concise as well as readable and thereby, Apache Flink reduces human latency. Besides described second-order functions, Apache Flink adds third-order functions for fix-pointing iterations.
Apache Flink’s Key Concepts For Reducing Technical Latency
Based on the declarative character of Apache Flink programs, further improvements for reducing the technical latencies are possible. The program results in a data flow graph consisting of higher-order functions. Now it is possible to derive optimization rules like push down of projections and filters or early and lazy grouping, as we already know them from database systems.
In Big Data Systems like Apache Spark, iterations are implemented as iterations by looping. Thereby, an external program executes the loop and the immediate results are even stored after each completion of the loop body. Apache Flink provides two optimizations in its third-order functions for loop.
First, Apache Flink implements iteration in data flows and thereby adds a direct feedback loop in the looping function. The operation starts with a partial solution, the operations in the loop body are applied to the partial solution and then, it will be checked if the fix point is reached or not. If it is reached, the loop is done. If it is not reached, the initial partial solution of the beginning is replaced and the cycle starts again. Due to the query optimizer’s possibilities to push work out of the loop, to cache loop-invariant data, or to maintain state as an index, processing of the loops becomes more efficient.
Second, Apache Flink implements delta iterations whose application requires sparse computational dependencies. Thereby, each iteration considers and evolves only a part of the whole data. After each iteration, the delta that has to be considered shrinks and thus, a performance improvement is achieved compared to the processing of the entire data in each iteration.
Due to such optimizations in handling iterations, Apache Flink attains way better performance compared to Apache Spark or Apache Hadoop.
To put it in a nutshell, Apache Flink’s success can be measured within various dimensions. A declarative code structure and well-thought-out patterns help developers write more concise code. This reduces the human latency. Furthermore, the automatic query optimization, as well as particular implementation improvements in handling iterations, reduce technical latency measurably. Finally, there are various companies, like Alibaba Group, Bouygues, or AWS that practically use Apache Flink for their daily operations.
Analysis of Heterogeneous and Distributed Data Streams in the IoT
The Internet of Things (IoT) brings new challenges to the analysis of data streams. Applications of the IoT can contain millions of data sources that are highly distributed and highly dynamic. Furthermore, these systems may consist of heterogeneous hardware components and data formats.
Apache Flink, as presented in the previous section, and other existing Data Management approaches assume a homogeneous compute cluster on which the executions can be mapped. There existed two types of Data Management systems. Systems of the first group (e.g. Apache Flink and Apache Spark) are based on the so-called cloud paradigm and require the data to be collected centrally before further processing. For instance, Apache Spark or Apache Flink belong to the first group. Systems of the second group (e.g. Frontier) are based on the fog computing paradigm and only scale well inside the “fog” and do not make use of all capabilities of modern cloud infrastructures. Frontier represents an instance of the second group. Both architectural concepts lead to a bottleneck for IoT applications with requirements as specified above.[15]
The newly arising question is: how can a system be designed to offer reliable and efficient Data Stream Management for the IoT? Thereby, some concrete challenges exist:
- For a particular data source, where should the data be processed so that network traffic is minimized and security, as well as privacy, are maximized?
- How to generate code for different hardware devices and sensors to enable the usage of heterogeneous hardware components?
- Which powerful intermediate representation allows optimizations of such heterogeneous data analysis programs for different data processing workloads?
- How to handle error detection and intervention decentralized to deal with the spontaneous, potentially unreliable connectivity of IoT infrastructures?
- How to optimize the distributed processing topology dynamically to optimize long-running systems on the fly?
To tackle these challenges, the NebulaStream platform was created. It supports:
- data sharing among multiple streaming queries, on stream aggregations, as well as acquisitional query processing and on-demand scheduling of data transmissions,
- distributed query compilation for different query, hardware, and data characteristics,
- diverse data and programming models, a centralized management view, as well as a unified intermediate representation that performs optimizations across traditional boundaries,
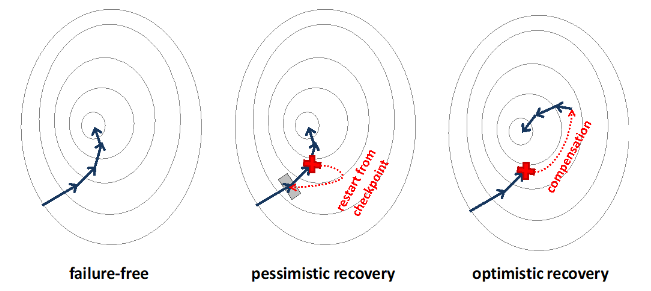
- different failure recovery approaches on all layers of its topology,
- and constant evolution under continuous operation.[16]
These features aim to reduce human and technical latency. The NebulaStream platform is a joint research project led by the IoT Lab at the Berlin Institute for the Foundations of Learning and Data and is still actively developed.[17]
Methods and Technologies for a single data infrastructure for AI-Applications
With data being a necessity for production nowadays, industries would stop working if this factor is not available. Thus, a strong and reliable infrastructure is needed to keep data highly available. Over the years, methods and technologies have been developed to make this possible. Even enable AI-Applications to use these infrastructures. This resulted in Data Management Systems that can be used for storing vast amounts of data, and for Machine Learning. Examples of such Data Management Systems are the Sloan Digital Sky Survey[18] and IBM Analytics[19] (former Many Eyes). The Sloan Digital Sky Server takes astronomical data, stores it, and makes it accessible for the public, which can now run queries on new astronomical findings. It is possible to do that since the data analysis itself is separated from the field of astronomy. Thus, citizens are able to play with data and find new connections. This can even help the people working in the field. IBM Analytics works similarly. It was developed by IBM and uploads data sets that people can use, visualize, share information and build upon it in their own algorithms and programs.
All this builds a Data Analytics Ecosystem, where interdependencies, cross-platform availability, and algorithms with handy tools generate a processing infrastructure that simplifies Data Management and Data Mining. Thus it should be an open and protected space for developers, users, data providers, and services alike. Although ecosystems like this could be set up around a market, making it open source and freely available gets rid of one major problem we are facing in the Data Mining world. A lot of services are built, but there are not enough developers to maintain these efficiently, only the open-source community could do it.
One of such open-source ecosystems is AGORA[20], a so-called “One Data Management for AI-Applications”, which is the focus of current research activities. It provides blocks for building a Data Mining infrastructure. AGORA makes multi-platform, compliant distributed, and trustworthy data processing possible and also supports the debugging of data analysis programs. For instance, usages in healthcare and digital humanities are conceivable. However, there are a few difficulties AGORA and many other similar platforms are facing: First, how to ensure a compliant and/or trustworthy query processing. Second, how to design the pricing of information marketplaces, since data is a factor of production and a new form of currency. If these problems are solved, such ecosystems will be the go-to for AI-Applications.
Summary
Prof. Markl presented data as a new factor of production for sciences, humanities, and industry. To make the best use of Data Management processes, the main goal is to reduce human and technical latency. The reduction of human latency can be reached by providing an intuitively usable system, while the reduction of technical latency can succeed by the smart distribution of work and the development of more efficient algorithms. Such systems enable real-time applications for data analysts.
Over the years, important technological foundations were built by research in the field of Data Management. Prof. Markl summarizes an extensive evolution of Big Data platforms, starting with Data Warehouses in the first generation, continuing with systems such as Apache Hadoop, Apache Spark, and concluding with Apache Flink in the fourth generation.
Systems such as Apache Flink already provide automatic optimization of algorithms, parallelization, and hardware adaption as well as methods for distributed analysis of large datasets. But as the next steps in the progression of Big Data platforms, methods for the analysis of massive data streams out of the IoT as well as Data Management infrastructures for collaborative AI innovations must be developed. The current work of Prof. Markl and his colleagues, e.g. NebulaStream and AGORA, illustrate the active research efforts that are trying to solve these challenges. But still, Data Management research is an interdisciplinary field within and outside computer science and thus, many more challenges will follow for future work.
[1] European Big Data Value Forum: “Volker Markl.” Last accessed on 14.01.2022. https://2020.european-big-data-value-forum.eu/keynotes/volker-markl/.
[2] ibid.
[3] Database Systems and Information Management Group: “Prof. Dr. rer. nat. Volker Markl.”
Last accessed on 16.01.2022. https://www.dima.tu-berlin.de/menue/staff/volker_markl/.
[4] ibid.
[5] BIFOLD: “Prof. Dr. Volker Markl.” Last accessed on 16.01.2022. https://bifold.berlin/de/person/prof-dr-rer-nat-volker-markl/.
[6] https://mlhub.earth/data/bigearthnet_v1.
[7] Markl, Volker: “Mosaics in Big Data” Lecture Series on Database Research, 04.01.2022. https://www.tele-task.de/lecture/video/8942/.
[8] Markl, Volker: “Mosaics in Big Data” Lecture Series on Database Research, 04.01.2022, slides p. 47.
[9] http://stratosphere.eu.
[10] More information on Apache Flink can be found here: https://flink.apache.org.
[11] Database Systems and Information Management Group: “Dissemination of Research Results. Flink / Stratosphere”. Last accessed on 16.01.2022. https://www.dima.tu-berlin.de/menue/research/dissemination_of_research_results/.
[12] Ji, Hangxu, et al. “Multi-Job Merging Framework and Scheduling Optimization for Apache Flink.” Database Systems for Advanced Applications, Springer, vol. 12681, 2021.
[13] Reza, HoseinyFarahabady M, et al. “Q-Flink: A QoS-Aware Controller for Apache Flink.” 19th International Symposium on Network Computing and Applications (NCA), IEEE, 2020.
[14] Sahal, Radhya, et al. “Big Data Multi-Query Optimisation with Apache Flink.” International Journal of Web Engineering and Technology, vol. 13, 2018.
[15] Zeuch, Steffen, et al. “The NebulaStream Platform for Data and Application Management in the Internet of Things.” 10th Conference on Innovative Data Systems Research (CIDR), 2020.
[16] ibid.
[17] More resources on the NebulaStream platform can be found here: https://nebula.stream.
[18] More on the Sloan Digital Sky Survey can be found here: https://www.sdss.org/.
[19] More on IBM Analytics can be found here: https://www.ibm.com/analytics.
[20] https://agoradata.com/.