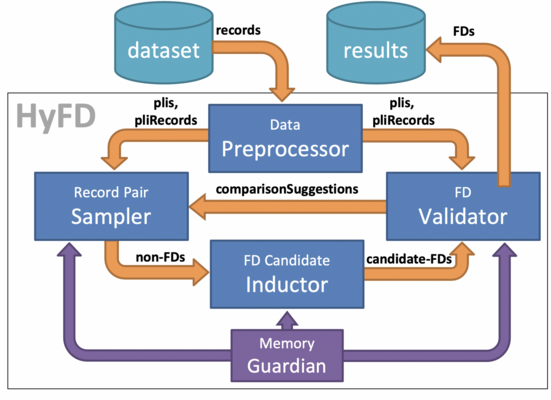
Overview of the Lecture
In the lecture “Data Profiling: a Primer” Prof. Felix Naumann gives an engaging overview of current trends and topics in the field of data profiling. In particular, he first introduces the field and its applications and gives an overview of basic statistical approaches. Then, he presents his group's research results on three data profiling challenges: detecting unique column combinations, functional dependencies, and inclusion dependencies. Finally, he concludes with an outlook to further dependencies and other challenges.
Introduction to Data Profiling Tasks and Use Cases
Data profiling is the practice of reviewing and analyzing data to develop useful summaries. The procedure produces a high-level summary that users can use to identify data quality concerns, hazards, and general trends.
Data profiling use cases include query optimization, data cleansing, and data integration.
It can be used together with an ETL (extract, transform, load) procedure to cleanse, enhance, and load data into a destination location.
Profiling Tasks
Data profiling tasks appear at various granularities, especially in a database context. We can profile single columns to provide a better knowledge of the frequency distribution of various values, types, and uses for each column. Meanwhile, we can also profile the relation between multiple columns to discover properties, such as correlations between the columns. Finally, a dependency analysis can reveal hidden dependencies between different columns (not necessarily from the same table).
Single-column data profiling techniques include descriptive statistics, such as minimum, maximum, mean, or percentile. Further examples are calculating the standard deviation, frequency, variation, or aggregates, e.g., count and sum. Additionally, metadata, such as data type, length, uniqueness, or occurrence of null values can be of interest. We can use this metadata in turn to cleanse the data. For example, if we know that one column contains only unique values, we can easily filter out the faulty values that violate this uniqueness constraint. Further applications of this metadata are misspelling detection or finding missing values.
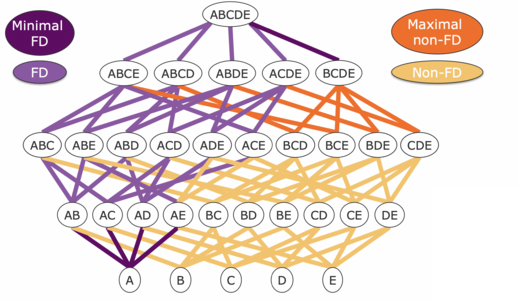
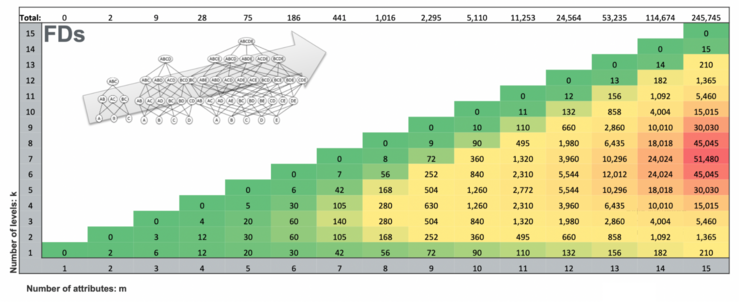
In the following, we are going to focus on three data profiling tasks for discovering data dependencies. The tasks include functional dependency discovery, uniqueness detection, and inclusion dependencies detection between different tables (indicating a foreign key relationship).
To make data profiling easier, purpose-built tools are usually utilized. When progressing from single column to single table to cross-table structural profiling, the computing complexity tends to increase. As a result, performance is a factor for evaluating profiling tools.
Data Profiling Use Cases
Data profiling use cases span a wide range of applications that we can perform once we have gained knowledge of the underlying data and profiled it.
One application is query optimization, where single-column profiling data, such as histograms and counts can help the optimizer of a DBMS to estimate cardinalities. As previously mentioned, data profiling can also be helpful for data cleansing. Here, the knowledge of data properties, such as the uniqueness of a column allows us to identify all violations of it. Furthermore, detecting dependencies across datasets is helpful for data integration tasks, e.g., finding foreign key relationships through inclusion dependency detection. Further use cases for data profiling are scientific data management, data analytics, and database reverse engineering.
Unique Column Combinations and Keys
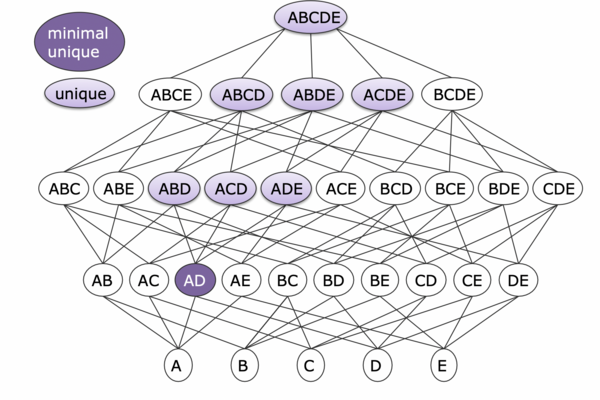
Unique column combinations (UCCs) extend the concept of unique columns. A column is unique if it has only unique values. Similarly, a column combination is unique if we have only unique value combinations from these columns. One can also say that the attributes of a UCC contain no duplicate entries in its projection.
Use cases
The knowledge of UCCs is crucial for defining key constraints for a relational dataset. For a set of columns to be a key, it is a necessary condition for them to be a UCC. However, only a domain expert can decide if a set of columns can be a key, because the possibility exists that the uniqueness of the values is just there by chance.
Typically, we are interested in finding minimal UCCs, where we can not remove a column without losing the uniqueness so we can find minimal keys. Additional use cases for UCCs include schema normalization, data cleansing, query optimization, and schema reverse engineering [4].
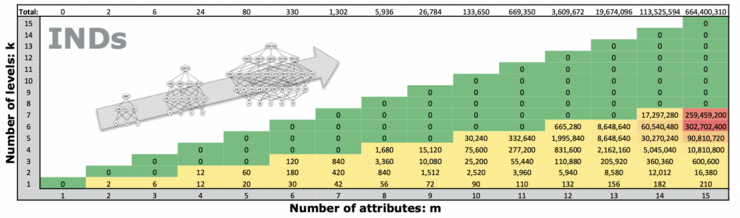
Problem Space
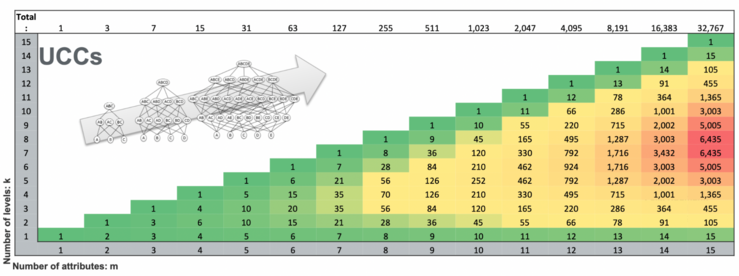
For a given table with m attributes, the number of possible UCCs of size k is m choose k. Thus, for m attributes, the overall number of UCC candidates to check is in O(2^m), which is exponential.