Motivation
Definition of Provenance
Provenance is broadly defined as a description of the production process of some end product using meta-data. Both, the end product as well as the production process leading to the product can be very diverse. For instance, a product can be almost anything from natural products to data analysis. Therefore, their production processes are equally diverse and can range from supply chains to on-site constructions to data pipelines or other processes. Meta-data on the other hand is data that describes the production process and may include, for example, information about who was acting at a particular time or what inputs led to a certain output.
Advantages of Provenance
Provenance in general brings three advantages: Understandability, reproducibility and quality. Understandability means the ability to explain the end product or the result of a production process and makes it transparent for the parties involved. With good provenance, it is possible to describe exactly how an end product was developed. Reproducibility is defined as being capable of recording anything that leads to a specific result and thereby enables the opportunity to check a prior result by restarting with the same materials and methods following the same process to produce the result again. In addition, provenance can increase quality by ensuring given needs and requirements, as well as helping to trace back errors or identify opportunities for improvement.
The lecture presents three potential day-to-day applications of provenance. In supply chains, trust and traceability is essential to address ethical concerns of customers. An understandable production process mitigates the risks of misinformation on ingredients of a product or worker exploitation. For scientific experiments, preservation and repeatability are key aspects. Provenance can help to ensure reproducibility by exactly documenting the whole process. This enables scientists to reproduce their results even many years after the initial experiment. Lastly, the increase in quality can help at processing complex data. The analysis and debugging of big data pipelines and workflows can be optimized by reducing errors or using other methods which will be covered later.
Data Provenance
Provenance is very diverse and essentially depends on four dimensions. First, there is the purpose for which provenance is used, e.g. performance improvement or traceability . Next is the type of process for which provenance is collected. For example, provenance in supply chains looks very different from provenance in data pipelines. Another dimension is the type of data being considered, such as nested data, text data, or relational data. Lastly, the environment, in other words, the application conditions, e.g., whether the application should run fast or be scalable, must be considered. Depending on all these factors, the concrete provenance will look different in each case.
In general, there are four types of provenances that can be modeled as a pyramid, with one type becoming more specific to the process the closer it is to the top of the pyramid. The most general type of provenance is provenance itself, which can relate to any end product or process. Above that is provenance of information systems, where the process is limited to the exchange of digital data. At the next level, processes are further restricted to workflows, which are typically modeled as graphs. At the top layer is data provenance, which includes SQL queries or more generally data pipelines with operators that have well-defined semantics and can therefore be used for precise provenance. It is important to note that as the specification increases, so does the level of instrumentation, which is the ability to integrate the collection of provenance into the production process.
Models of Data Provenance
As the remainder of this summary focuses on data provenance, provenance as well as data provenance will be used interchangeably.
Two main types of provenances can be distinguished, namely provenance for existing data and provenance for missing results. Both types can be further subdivided into three additional groups respectively.
First type of provenance is provenance for existing results, which is metadata about the production of the data in the query result. Its subcategories include Why-Provenance, which describes what data in the database lead to the production of the output, How-Provenance that provides additional information about how the tuples from the database are combined to produce the output, and finally, Where-Provenance, which specifies which table or cell the actual data is copied from.
The second subset of data provenance is provenance for missing results, which is metadata that explains why some expected data is not present in the query result. Again, there are three sub-models. Starting with Instance-based provenance, which locates missing data in the source database and describes what data is missing to actually get a desired missing tuple in the query result. Second, Query-based provenance finds one or more query operators responsible for pruning the data that would have otherwise resulted in the missing tuple. And lastly, Refinement-based provenance rewrites the query, if possible, to obtain the missing result.
Lazy and eager algorithms
Algorithms for data provenance can be classified into two categories. Lazy algorithms compute the provenance on-demand based on input data, the query as well as the resulting output, while eager approaches add additional meta-data to the query output such that it can be easily derived where the data comes from.
Lazy computation of data provenance
The lazy method of computing provenance starts after a query was processed on a database and the provenance information is requested for the specific output tuples. The on-demand tracing is based on the input data to a query, the query itself and the output data. No provenance information is computed in advance.
Lineage tracing for why-provenance is an example of lazy data provenance. Lineage is defined as a subset of the original dataset that is sufficient to produce the result tuple. The approach tries to find a precise lineage. Therefore, for every operator being part of the query, the result tuple will be traced backwards. Based on specific properties of the operators, it can be found out which tuples were necessary for computing the next intermediate result. The algorithm stops at the leaf level of the operator tree, including only tuples relevant to compute the final result.
Eager computation of data provenance
Eager computation of data provenance begins before the actual query processing. In the database, every data tuple is annotated with a unique identifier. During the query processing, these annotations are maintained to compute the final result containing encoded provenance annotations for every resulting tuple.
These annotations are called structural provenance. For every available operator, the semantics are extended to also trace structural provenance by adding it to the result tuple. For a join, this structural provenance would be information on data dependencies, paths recording the attributes that the operator relies on to produce the tuple and a set of pairs mapping access paths of the input tuples to paths of the result tuple to describe restructuring.
An example for eager computation of data provenance is the tracing of nested data in big data pipelines. Queries on nested data not only use standard relational algebra but also a nested relational algebra. For every operator in the data pipeline, the intermediate query result is added with structural provenance depending on the operator's semantics.
At the end, the annotated result data as well as the tree-pattern of the considered nested tuples are combined to calculate rewritten tree-patterns that can be applied to the source data and thereby indicate the origin of a data item in the result tuple.
Query-based provenance of missing results
To explain why data tuples are missing in the resulting output of a query, Query-based provenance can be applied. The goal is to identify those query operators that cause relevant data for a specific result to be excluded from processing. It relies on lineage tracing to detect operators that contain the relevant data in their input but not in their output.
In the first of three steps, the algorithm searches data that could lead to the desired output tuple that is missing in the result. After that, in the query operator tree, it traces all successors for every operator and returns the operators that cause the mistakenly excluded tuple.
Systems for data provenance
Professor Herschel presents four of her research projects on systems for data provenance which will be described in the following part.
Data pipeline debugging
The first research project is about debugging big data pipelines with respect to missing results. It aims to combine the tracing procedure for nested data presented in the part on eager computation and structural provenance above with the later described query-based provenance of missing results and additionally demands the resulting system to be scalable. However, simply using structural provenance for data tracing to extend all parameterized operators makes the system inefficient and is not scalable. In big data systems, another approach has to be researched.
The solution presented in the lecture redefines query-based provenance to be based on reparameterizations rather than lineage. This implies that provenance reasons about potential parameter changes that would yield the expected result instead of tracing back every operator. Because of the NP-hard difficulty of such problems, the research team developed heuristic algorithms. While state-of-the-art solutions are only able to detect a minority of explanations and cause many incomplete or incorrect results, the presented system finds all errors in the scenarios based on TPC-H queries which are accepted as a gold-standard in the industry.
Data usage pattern identification
Another use case for provenance is the identification of data usage patterns. Here, the idea is to use structural provenance to determine the access patterns on the data for a query workload. This allows, for example, to distinguish hot items, i.e. data that is frequently accessed, from cold items, i.e. data that is rarely or never accessed. This classification of data can help in deciding which partitioning is beneficial. For example, if the structural provenance indicates that there are many columns consisting only of cold items, it is worth applying vertical partitioning and splitting off the less frequently used attributes into another table. Similarly, vertical partitioning can be applied if only certain rows of a table are used. Furthermore, the access patterns can be used for choosing a caching strategy, such that only hot items are cached. Generally speaking, provenance helps to increase the performance of data processing.
Visual data exploration recommendation
Melanie Herschel's work shows an application of provenance in the context of visual data exploration where provenance can be used in the recommendation algorithm to improve the quality of the resulting recommendation.
A user study that was conducted by the IPVS showed that EVLIN++, the provenance-based recommendation system they developed, outperformed an alternative state-of-the-art system called Voyager. The participants were divided into two groups. One group used and explored the EVLIN++ system for 30 minutes and the other group explored the Voyager system. When the participants got an interesting result, they had to record it and give the result a score of how interesting it was. Even though the study showed that the users looked at less visualizations using their developed EVLIN++ system, they still made more interesting findings.
This novel approach of using provenance could be used in future work for various visual data exploration systems.
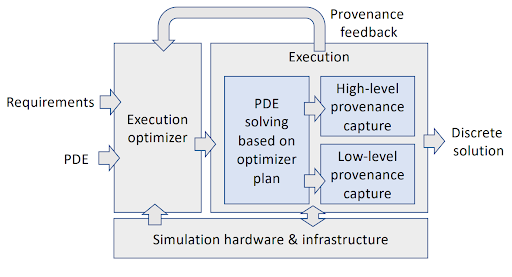
Simulation optimization
Partial differential equations (PDEs) are needed in many fields (e.g. fluid dynamics, structural mechanics or social sciences) to model complex mathematical processes. Usually, numerical methods are used to calculate the solutions. Such methods require a large number of parameters, which in turn strongly depend on the PDE. Currently, the choice of which numerical method to use with which parameterization is based on the expertise of experts as well as on trial-and-error.
Provenance can help to quantify the behavior and performance of schemes for solving PDEs under given conditions and support the selection of the optimal scheme including the parameterization for a given PDE.