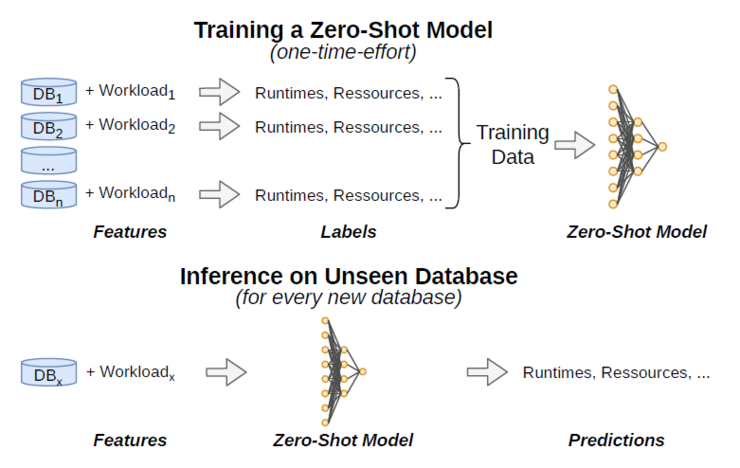
Another key challenge is the collection of sufficient training data as well as the resulting robustness of the trained model. The question now is, how many databases and workloads are necessary to train a model that properly generalizes across databases? A relatively small number of databases is sufficient to generalize robustly to already outperform the existing approaches. This amount of training data can be estimated by evaluating the generalization performance on holdout databases. When the generalization performance stagnates on unseen data the training data should be sufficient. Another question is how to assemble useful training databases and workload, which ideally contain different characteristics.
Lastly, capturing data characteristics (e.g. data distributions) and systems characteristics (e.g. runtime complexity) should be separated and not internalized in one model. As data characteristics are different for new databases and therefore not transferable, this separation is necessary. Hence, these data characteristics (e.g. estimated cardinalities of operators) should be captured in an additional data-driven model, which then informs the zero-shot model. This does not contradict the zero-shot advantage of the one-time model training, as data-driven models are derived from a database without collecting output of training queries, so an update of the data-driven model for the new database is enough.
Example: Zero-Shot Physical Cost Estimation
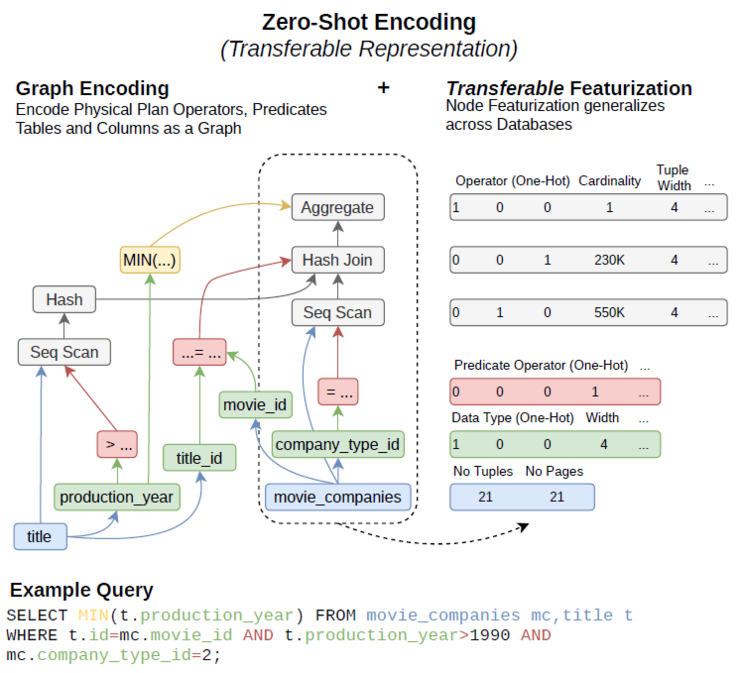
Zero-shot learning can be applied to multiple database tasks, e.g. physical cost estimation, design tuning, query optimization and planning. In the example of physical cost estimation the runtime of a given query plan should be predicted through transferable query representation. Physical cost estimation was previously done with simple cost models or workload-driven models, which required to run many queries to train a model. Zero-shot learning improves the approach by generalizing across databases and workloads while using the same model on unseen databases to get predictions. Each node of the graph represents a physical operator, which captures the differences in runtime complexity. As transferable features the nodes represent tables, columns, aggregations and predicates. The zero-shot model then learns the system characteristics separate from the data characteristics. This means the model only encodes the predicate structure and uses estimated cardinalities from a data-driven model. The model learning consists of a GNN-like architecture, which in the end enables a runtime prediction for a query plan on a new database.
Results and Evaluation
The zero-shot approach was evaluated in the context of physical cost estimation, envisioned to be a building block for zero-shot models for many other DBMS tasks. The main premise is that a trained zero-shot cost estimation model can predict the query runtimes of a new database out-of-the-box. The prototype system designed to evaluate the approach used the transferable query representation previously introduced.
Unlike in workload-driven learning components, the zero-shot model learns system characteristics separately from data characteristics, and as such only encodes predicate structure and utilizes estimated cardinalities from a data-driven model or the query optimizer as input for the cost estimation.
The evaluation model was trained on 19 databases as it was found that after 19 databases performance stagnated. This indicates that even a moderate number of databases are sufficient training data for the model to generalize to other databases.
The zero-shot model was compared to two workload-driven approaches (MSCN and E2E) as well as a simple linear model using the actual runtimes from the internal cost metric of the Postgres optimizer. Additionally the zero-shot model was tested using estimated cardinalities obtained from learned estimation and exact cardinalities. The workload-driven models were trained on different training sets ranging from "small" training set sizes of 100 queries to large training dataset of 50,000 queries. The training workload for the zero-shot model was comparable to that of the large training sets for the workload-driven models, but had to be only executed once and could then generalize to many databases while the workload-driven training had to be executed for every new database.
The approaches were compared using the median Q-Error which indicates how far the prediction deviated from the actual runtime. As the zero-shot approach is not trained on the actual database used for evaluation while the workload-driven approaches are, the results from different numbers of training queries are compared. The benchmarks utilized for comparison are scale, synthetic and job-light.