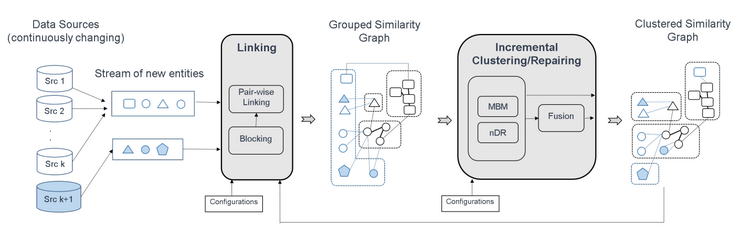
FAMER is one of the few tools that natively support incremental clustering and repair. New entities that arrive are grouped amongst themselves and are linked to the existing entities. In the next step of the FAMER pipeline, the newly grouped entities are integrated into the clusters. We can distinguish between two methods to integrate the new groups of entities:
Non-repairing with Max-Both Merge (MBM): A new entity group is added to a similar, already existing cluster, if there exists an entry in the new group and an entry in the old cluster that both have a maximum similarity link and if the respective clusters of the entity-pair contain only entities from different sources. Otherwise, the new entity group forms a new cluster.
Repairing with n-Depth Reclustering (nDR): This approach considers a reclustering of existing clusters, thus allowing to repair existing clusters, to achieve a better cluster assignment for new entities. However, if everything would be reclustered for every new entity, this approach would not be efficient. Therefore, this approach only considers the n-depth neighbors that are linked in the similarity graph. A 1-depth reclustering would only consider direct neighbors, while a 2-depth reclustering for example would also consider the neighbors of the direct neighbors and so on.
In an evaluation, these approaches were benchmarked against existing solutions and the 1-depth reclustering approach was able to achieve almost the same results as the non-incremental approach, while at the same time being much faster. With this evaluation, it was shown that the quality of nDR does not depend on the order in which the entries arrive.
In summary, it can be said that with the rise of big data systems, the need for multi-source entity resolution is growing. Data integration still faces many challenges such as data quality, privacy support for continuous change, and automation of large-scale knowledge graphs.
With FAMER and the incremental clustering approach a huge step is already taken, nevertheless, numerous challenges, such as incremental entity resolution for many entity types or learning-based classification of new entities, are still open. So far, we have only looked at entity resolution of textual data. However, data often also consists of images or audio data, thus opening the need for further research in the field of multimodal entity resolution.
Sources
Famer Incremental Pipeline: Saeedi, Alieh. "Clustering Approaches for Multi-source Entity Resolution."
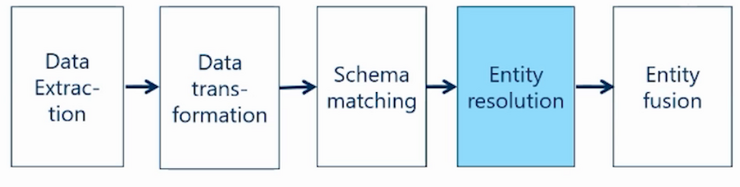
Figure 1: Slides Lecture by Prof. Erhard Rahm, https://www.tele-task.de/lecture/video/9028/
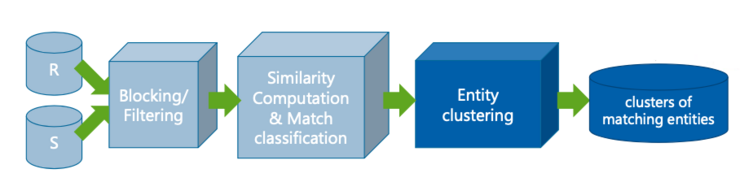
Figure 2: Slides Lecture by Prof. Erhard Rahm, https://www.tele-task.de/lecture/video/9028/
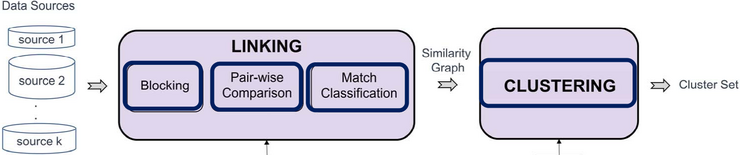
Figure 3: Slides Lecture by Prof. Erhard Rahm, https://www.tele-task.de/lecture/video/9028/
Figure 4: Famer Incremental Pipeline: Saeedi, Alieh. "Clustering Approaches for Multi-source Entity Resolution."