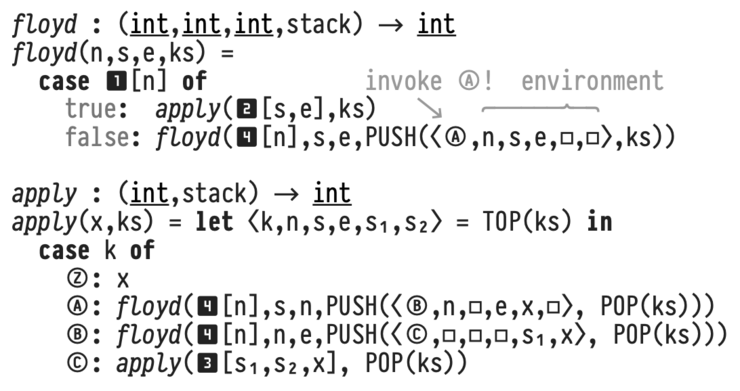
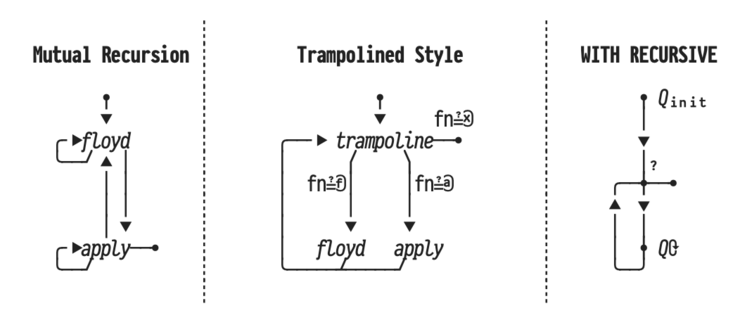
Evaluation of the approach
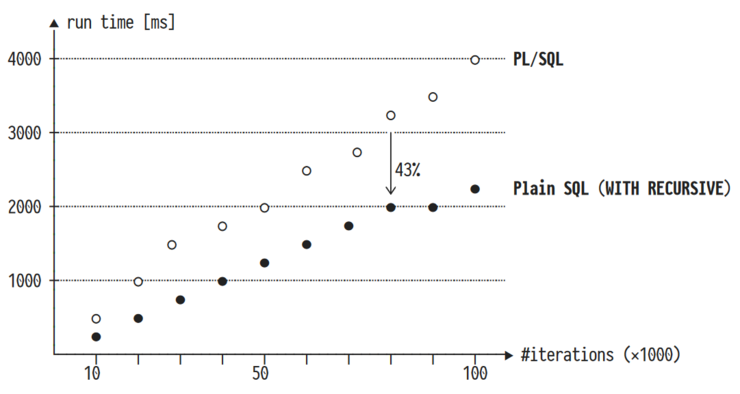
Using the approach described above, we reach a speedup of one order of magnitude. The average overhead of a classical UDF evaluation in SQL is 95%. The DTW function can be sped up by a factor of 15.6.
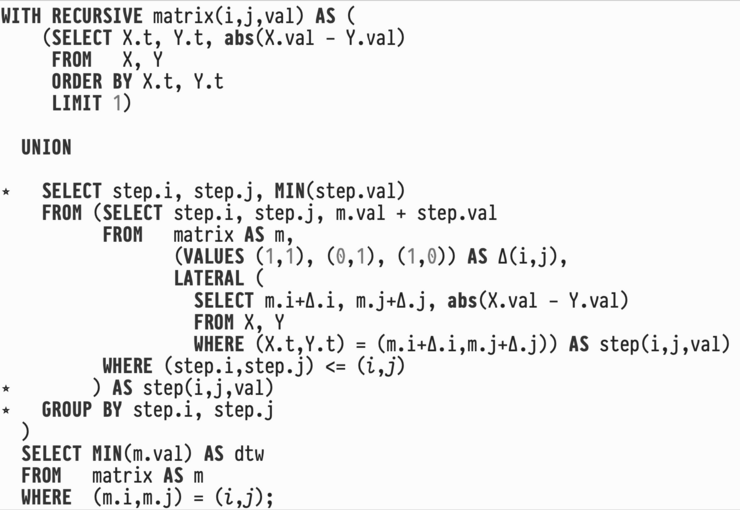
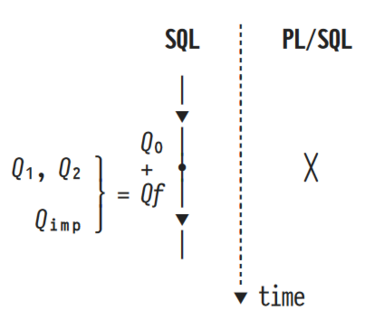
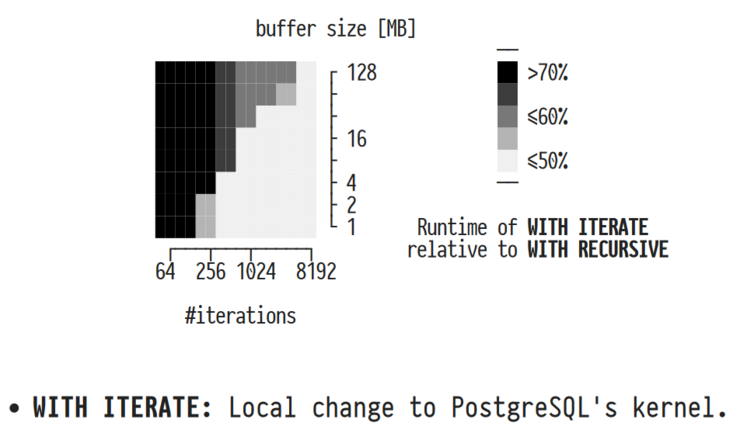
The approach treats UDFs as functions and does not require a change in the RDBMS kernel, as it only transforms SQL to SQL.
Algorithms that can be described in SQL only, are among others CYK parsing, distance vector routing, traffic simulation. With this in mind, the approach by Prof. Grust allows large improvements in working with data-intensive workloads. Thus, it moves the computation closer to the data, as proposed by Mike Stonebraker.
Summary
As a part of his work as the lead of the database research group at University Tübingen, Professor Torsten Grust works at the intersection of database research and programming language technology. This is done by taking interesting aspects of programming languages (PLs) and extracting them back into the field of databases. The goal is to improve the execution performance of SQL queries. As SQL is Turing complete since the addition of recursion in SQL:1999, operations are moved as close to the data as possible.
In his lecture, Prof. Grust provides us with insights on how PL/SQL, a procedural language to complement SQL, as well as UDFs cause inefficiencies at runtime, and how we can change them into plain SQL to improve query execution performance. Working with PL/SQL, context switching between PL/SQL and SQL is computationally expensive and needs to be prevented as far as possible. Prof. Grust presents his approach to compile PL/SQL code to pure SQL code which decreases the runtime by more than 50%. One presented approach is to introduce tail recursion for the WITH RECURSIVE SQL function to reduce the amount of memory used. Furthermore, an approach to treat user-defined functions (UDFs) as real function calls is presented, which allows a speedup in one order of magnitude.
Sources
Content is based on Prof. Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute. A recording of the lecture is available at https://www.tele-task.de/lecture/video/8906/.
Further sources:
[1] Grust, T. (2021). Datenbanksysteme Tübingen | Torsten Grust. Accessed on Dec. 18. 2021, https://db.inf.uni-tuebingen.de/team/TorstenGrust.html
Images
[1] Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute, page 11
[2] Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute, page 14
[3] Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute, page 28
[4] Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute, page 31
[5] Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute, page 32
[6] Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute, page 40
[7] Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute, page 44
[8] Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute, page 55
[9] Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute, page 56
[10] Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute, page 57
[11] Dr. Torsten Grust's lecture PL/SQL and UDFs are Lousy - But we can do something about it held on Dec. 07 2021 during the Lecture Series on Database Research at Hasso Plattner Institute, page 58