At first the talk goes over some technical terms and concepts. Afterwards István talks about the assumptions he made during his research and then concludes challenges, requirements and how to solve these challenges. Then he proposes the full idea and the results of his research. In the end he summarizes the problems his idea solves and the challenges that still remain.
Background
FPGA
A FPGA (Field Programmable Gate Array) is a type of specialized hardware, that allows you to have code directly implemented inside your hardware. This is accomplished by turning code into logical blocks and structuring these into modules. These than can be used to create the corresponding circuits. HDL(Hardware Description Language) or something similar can be used to visualize and communicate the design of the FPGA. Of course the ability to have code implemented inside hardware, comes at the cost of code occupying chip space. This is especially prominent for conditional statements, since in hardware both paths will be built. But since we have both paths built there is at least a performance boost for conditional statements, when using FPGA's. In general, small specific tasks can be accelerated with FPGA's. However, depicting complex, large problems in hardware is often associated with space problems.
GDPR
The GDPR(General Data Protection Regulation) contains, like the name says, articles regarding the regulation of data protection. Simplified these are:
- Right to be Forgotten(Being able to completely delete data)
- Detect potential data breach
- All data is associated with a purpose
- Users can object selectively to the use of their data
- Protection against accidental loss or damage
- Adhere to standards regardless of physical data location
- Resist and detect malicious activities that compromise data
Building systems to comply by the regulations is no trivial task. Violations against these can be really expensive. Therefor many companies want to have systems in place, to automatically fulfill the regulations. But current solutions come at the cost of a significant performance overhead.
Rethink Processing in Storage Layer
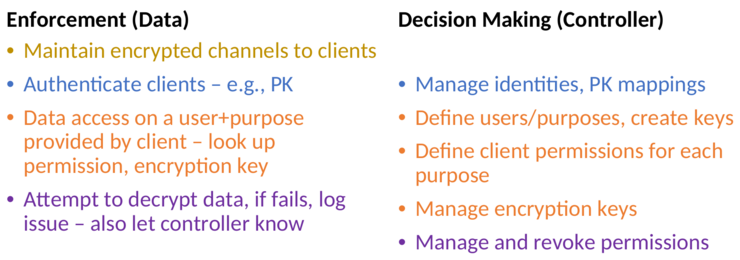
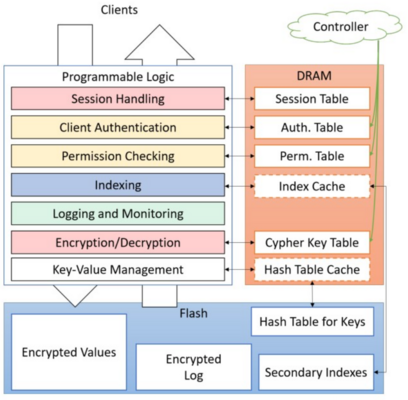
As explained in the introduction the general goal of the research was to make policy compliance available without / with less overhead costs. Therefore István encourages to rethink the processing inside the storage layer. Traditionally the overhead cost is attempted to be overcome with more specialized and more expensive hardware. In this section a software based approach will be shown as presented by István. Since the research was done in the field of policy compliance and GDPR the approach is called Software-Defined Data Protection (SDP) Before going into the more detailed solution of István, the first subsections will give an overview about context and assumptions and the heterogeneous hardware. These will lead to the implications and decoupling inside the storage layer. Finally, the SDP pipeline and the challenges of SDP are considered.
Context and Assumptions
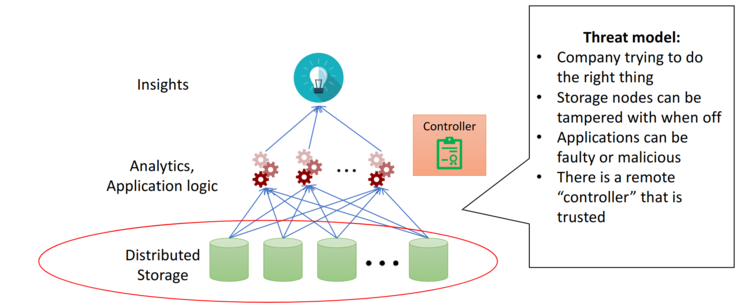
To understand the following approach better, the setup / context with its general assumptions will be shortly described in this subsection. In general the context is a company which stores it's data distributed. Further as shown in the figure (see Figure 1) the company tries to generate insights from this data by using analytics and other. The general goal is to support the processing in a GDPR compliant and more secure manner. The solution of István, which will be discussed in detail in the further section, is based on the following assumptions.
- Company it self is trusted and tries to do it correct.
- Storage nodes their self are not trusted, they might be tampered physical.
- Analytics and Applications can be malicious.
- A remote "controller" exists, which is trusted.