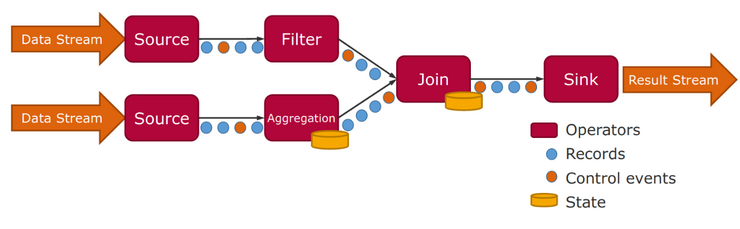
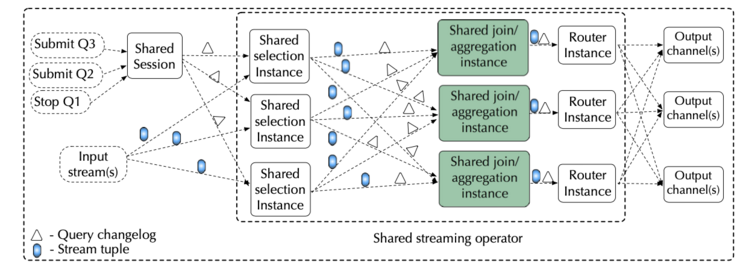
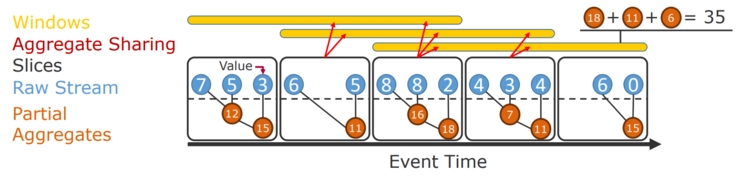
Architecture of a stream processing job
A stream processor typically consists of a number of operators that collectively handle the incoming information. Source operators accept the data stream and enrich the sources’ records with control events in set intervals, ensuring the coherence and validity of the stream. Further processing can be conducted either in a stateful or stateless fashion, depending on the particular purpose. In that respect, a Filter operator can be instanced as a stateless and time-agnostic operator. Conversely, Aggregation operators are stateful and require a means of determining when to output the aggregated result.
This is done by defining so-called windows on a stream. In essence, a window tells the stream processing engines how to divide a stream and when a collection of events is ready for processing. There are different types of windows, some of the more common ones are:
- Tumbling Windows (defined by the window length)
- Sliding Windows (defined by the window length and slide)
- Session Windows (defined by a “gap” in which no events are recorded, meaning for how long no events are registered before the window is closed)
In addition, the different concepts of time as mentioned above are also relevant when defining a window.
- Processing time windows are rather simple: The system measures the passing of time and will close the window once the time as defined by the window length has elapsed. Thus, the system decides the stream partitioning but will disregard any time information in the stream by doing so.
- In Counting Windows, as the name suggests, the system counts the number of events until a set value and will then start processing the events. Therefore they are similar to processing time windows.
- Event Time windows are based on the time information from the stream (when the event occurred at the source). These are more complicated to implement since delays in the network streams can be unordered regarding the event time. As a consequence, the system needs to have a notion of when to be certain that no more events belonging to the window will be arriving. This can be achieved by defining an upper-bound after which arriving events are disregarded.
Once a window is closed, the events belonging to the window can be processed. This is done by stream operators, which can aggregate the events using common functions such as min, max, average, sum, count, etc., or joining the events with events occurring in a different stream but in the same time window.
Research Topics in Stream Processing
Efficient Window Aggregation
One way of optimizing stream processing is by minimizing redundant computation and data replication when aggregating overlapping windows.
In many real-world scenarios, the window length is quite large compared to the slide. For example, one might be interested in health statistics of a server aggregated over the last hour with a one-second update time. This can be implemented as one-hour sliding windows with a slide of one second. Two adjacent windows will then have a high overlap of 59 minutes and 59 seconds, thus sharing most of the data. In a naive implementation, this leads to many copies of the data and lots of redundant computation. Here the idea of slices comes into play. A slice is a part of the stream that does not contain any window borders and thus can be reused between overlapping windows. In the case of sliding windows the slice has the length of the slide. For each slice, a partial aggregate is computed, which is reused for all windows in which the slice occurs. While this idea is straightforward for sliding windows, it can also be implemented for other window types, such as session windows.
Implementing efficient window aggregation in the stream processing engine Apache Flink resulted in orders of magnitude higher throughput depending on the numbers of concurrent windows than an implementation without efficient window aggregation.