Contents
- Introduction
- XStruct
- Downloads
Introduction
XML has become the defacto standard for electronic data exchange.
Although XML is that popular, not all XML data is accompanied by an
appropriate schema. The presence of a schema offers many advantages:
- XML data can be queried faster, because advance query pruning and
query rewriting can be employed.
- XML data can be validated with respect to conforming to
predefined formats. This is especially important when exchanging XML
data between parties.
- Automatic data integration often depends on the knowledge of the
schema of the data sources.
In order to gain these advantages, it is useful to extract the
schema of an XML document a posteriori automatically. While there are
already some algorithms known that fulfill this requirement, we adapted
and extended them in such a way that we are able to extract a common
schema for a collection of documents instead of just one on the one
hand and to be able to do this very efficiently, i.e., XStruct scales
very well to input documents' sizes.
XStruct was implemented by Jan Hegewald
in the context of a student research project.
XStruct
XStruct is our approach to automatic schema extraction and it is
implemented it as a Java program.
Features
XStruct's most outstanding features are:
- Extraction of general, complete, correct, minimal, and
understandable XML Schemas.
- Extraction of schemas from multiple documents.
- Extraction of schemas from large documents (> 1 GB).
- Detection of attributes of elements in the XML data.
- Detection of datatypes of the XML elements and attributes.
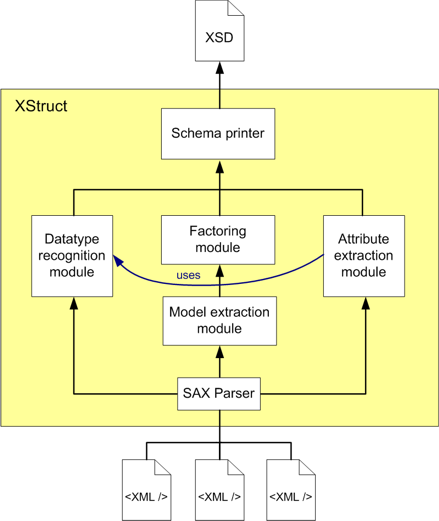
Architecture
The architecture of XStruct can be seen in the following figure:
While reading the XML documents, XStruct processes the data in three
modules: the model extraction module infers the content model for each
element, the attribute extraction module learns the attributes of each
element, and the datatype recognition module determines the datatypes
of the elements as well as of the attributes. The model extraction
module afterwards passes its output to the factoring module, which
consolidates all content models for one element into a common one.
Finally the schema printer module takes the output of the factoring,
the datatype recognition, and the attribute extraction module and
outputs the XML Schema file.
Syntax
XStruct is deployed as a single .jar-file and can be used as
described here.
XStruct offers two ways to configure the program. Either you can do
it with a configuration property file or with command-line options.
Depending on the alternative you prefer, there are two variants of call
syntax.
If you omit specifying an output file, the resulting schema will be
printed onto the standard output.
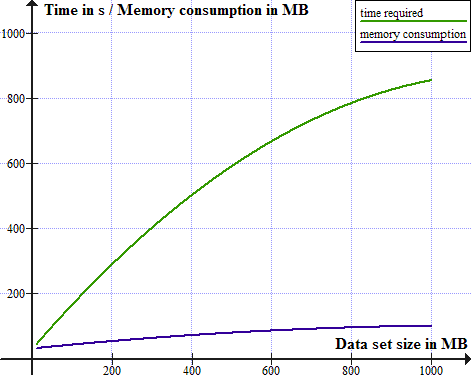
Scalability
See the following figure to get an impression of XStruct's
scalability:
Downloads
You can download the paper XStruct: Efficient Schema Extraction
from Multiple and Large XML Documents
which more deeply describes
our ideas, here.
The jar file: XStruct.jar
The manual: XStructManual.pdf
Terms of use
The software is free for academic purposes. We would very much
appreciate a short note or feedback on he usage. For commercial use
please contact Felix
Naumann.
Requirements
In order to use XStruct, you need to have Java 5 installed on your system.
Nothing else is required.