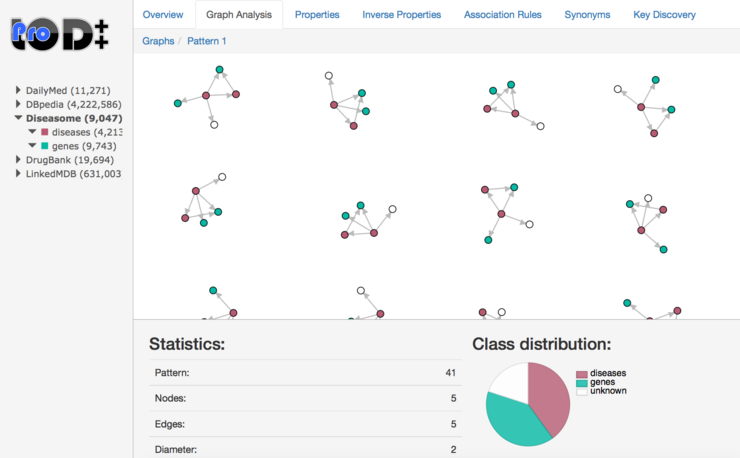
Anja Jentzsch, Christian Dullweber, Pierpaolo Troiano, Felix Naumann. Exploring Linked Data Graph Structures. In Proceedings of Posters and Demos Session, ISWC 2015, Bethlehem, PA, USA, October 2015.
Ziawasch Abedjan, Toni Gruetze, Anja Jentzsch, Felix Naumann. Profiling and Mining RDF Data with ProLOD++.In Proceedings of the IEEE International Conference on Data Engineering (ICDE), Demo, Chicago, IL, 2014.
Christoph Böhm, Felix Naumann, Ziawasch Abedjan, Dandy Fenz, Toni Grütze, Daniel Hefenbrock, Matthias Pohl, David Sonnabend. Profiling linked open data with ProLOD. In Workshops Proceedings of the 26th International Conference on Data Engineering (ICDE), Long Beach, CA, pages 175-178, 2010.