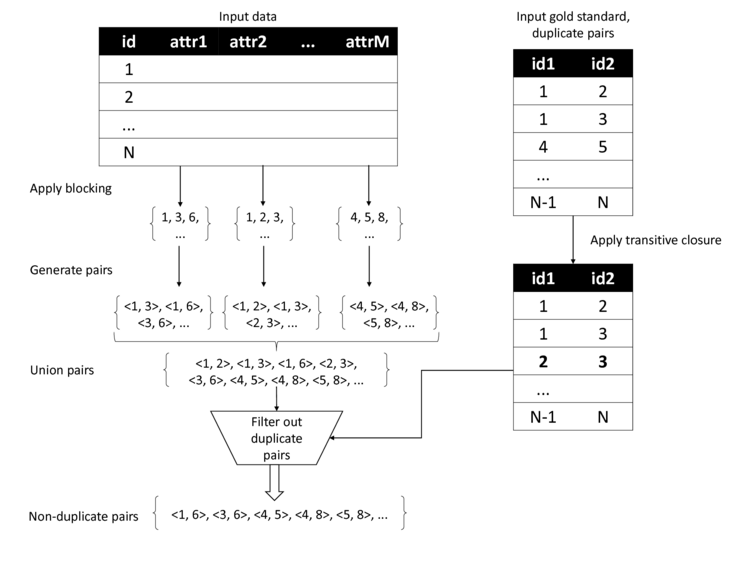
The gold standards that are available for many of the datasets used in our experiments each contain a list of record pairs that uniquely identify duplicate record pairs. In case this set is not transitively closed, we additionally create all transitive pairs and call this extended set DPL. To train and test a classifier, we also require a number of negative examples, i.e., non-duplicate pairs. When creating such non-duplicate pairs we should make sure that records are not paired up randomly, since such pairs are expected to be very different and therefore trivial to classify. More useful for training and more realistic for testing, however, is to expose the model to pairs that are harder to classify, corresponding to a more realistic scenario. In practice, to speed up duplicate detection, blocking methods [1, 2] are typically used to divide datasets into disjoint subsets, called blocks, according to a predefined partitioning key. To avoid false negatives, usually multiple partition keys are defined. It is important to select the partition key with great care, as it controls not only the size and number of blocks created, but also how similar the individual data records within each block are.
We perform a simple blocking by using each attribute of the currently processed dataset as a partitioning key. In case an attribute is multi-valued, we first divide it into its individual values and use those for blocking. Very unique attributes, which would lead to many single record blocks, are split into n-grams of 6 to 10 characters, depending on the length of the attribute, and then used as partition keys. As a result, we obtain several blocks, within which we create the cross product of all contained data records and thus form data record pairs, that are then combined into a common dataset. After making sure that there are no known duplicate pairs in the resulting dataset, we refer to it as NDPL. The NDPL dataset is, therefore, the set of all record pairs that can be formed within all blocks and does not include duplicate pairs. To achieve a reasonably balanced training set, we ensured that the ratio of DPL to NDPL is 1:10 by randomly selecting pairs from the NDPL dataset. Exceptions to this are datasets such as Cora, where we were unable to maintain the ratio of 1:10 without overly relaxing the blocking strategy.
The process is also shown in the following figure: