Motivation
When it comes to designing a database system, the traditional approach was always to optimize it for performance. Since the hardware on a physical server cannot be switched easily, data analytics tools were optimized for a certain hardware that was expected to be used for a rather long lifespan. Examples are the HyPer DBMS which optimizes for database systems with fast main memory [2] or Leanstore which optimizes for database systems with fast SSDs [5].
In the past years, it became a trend to move data and computations to the cloud, leading to some previous assumptions and principles being no longer true. For instance, hardware is not considered a constant factor anymore. It takes only a few clicks to exchange the hardware on which data is stored or computations are running. Moreover, instead of having hardware costs, operating costs, and maintenance costs, nowadays database owners only have to pay the cloud provider for the amount of scanned data or the amount of time a query execution took, respectively. Thus, there is a need for raising once again the question on what makes up a good data analytics system with regard to the possibilities of cloud infrastructure that is currently available.
This report presents a new benchmark designed particularly for database systems in the cloud as well as cost optimization as an alternative design principle for designing analytic database systems in the cloud. As this practice is highly dependent on business models offered by cloud providers, it is necessary to use efficient open data formats instead of proprietary structures, so that cloud storage providers can be switched whenever a cheaper offer is available without having to optimize for a new data format.
Currently, pricing models of data analytics services in the cloud appear to be rather arbitrary. For example, scanning a terabyte of data costs several dollars when using data analytics services in the cloud such as Google BigQuery or Amazon Athena. However, a rough calculation on how expensive such a pure scanning operation would be on a pure cloud computing platform such as Amazon EC2 yields only a few cents, which is magnitudes cheaper than any data analytics service in the cloud. This raises the question, whether and how it is possible to actually achieve those results in a cheaper manner.
Benchmarking for Cloud Analytics
The issue with current benchmarks for data analytics is that they do not consider typical conditions that apply to the cloud. For instance, the majority of benchmarks optimize for runtime, assuming ideal conditions of a system that does not process any other computations than the query execution. However, a cloud infrastructure is usually shared between multiple clients. Therefore, it doesn't make sense to optimize for runtime but rather for latency.
Only recently did van Renen \& Leis introduce the Cloud Analytics Benchmark (CAB) which is specialized for data analytics systems in the cloud [7]. It is based on the TCP-H benchmark which is commonly known as a state-of-the-art benchmark for data analytics. Other than TCP-H, it introduces multi-tenancy, i.e. the hardware holds multiple different-sized instances of a TPC-H database which are queried by different clients, representing the users of the cloud service. On top of that, the single queries arrive at varying times and asynchronously rather than one after another. Thus, the metric that is to be minimized is latency for every query, as it is the cost-driving factor in the business models of most cloud service providers.
The CAB is also able to measure how much it would cost to run on a certain cloud system. This can be useful for testing whether a provider with smaller prices per time is actually cheaper than another provider who charges more but might have a faster running system, thus being eventually cheaper. It can be also used to compare different pricing models such as price per time or price per query. It is, however, pointless to compare two providers who both charge per query, as the number of queries in the benchmark is constant.
Cost-Efficient Cloud Computing
When using a cloud computing service for query processing, it is easy to switch out the hardware used with only a couple of clicks. This implies that system design is no longer constrained by the long-term decision of hardware acquisition. Moreover, instead of having fixed acquisition cost, cloud computing services are usually paid based on the duration of the computation.
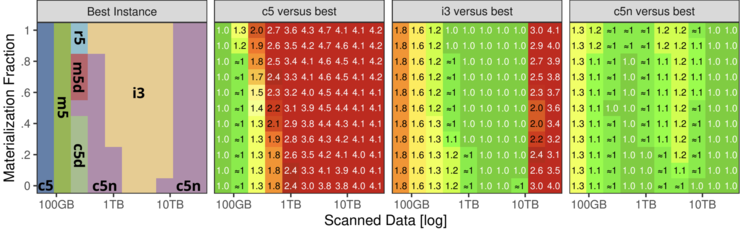
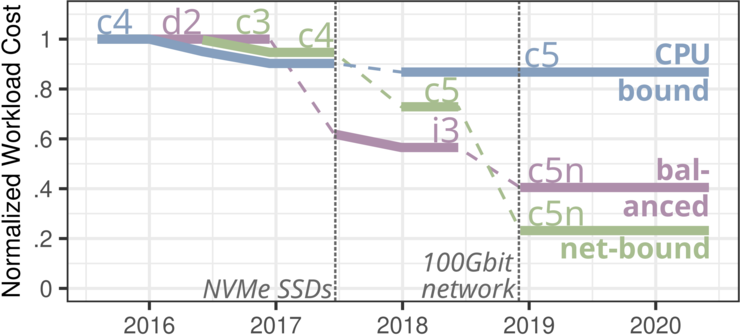
There are multiple different virtual CPUs offered by cloud computing services such as Amazon EC2. While some of them are optimized for fast computing, others are optimized for high network traffic whereas there are also instances using fast SSDs to better deal with outsourcing large amounts of data that do not fit into main memory. As outlined by Leis \& Kuschewski, comparing these three kinds of hardware instances for different workload sizes shows that the cost per workload is CPU bound for smaller workloads, disc bound for medium workloads and for large workloads eventually network bound. Moreover, although network optimized hardware instances outperform computing optimized and storage optimized instances mainly for large workloads, they even come fairly close to the best performing instances for small workloads as well [6].