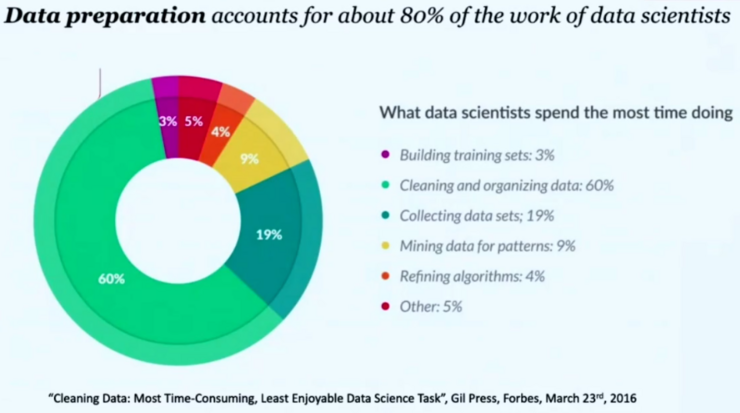
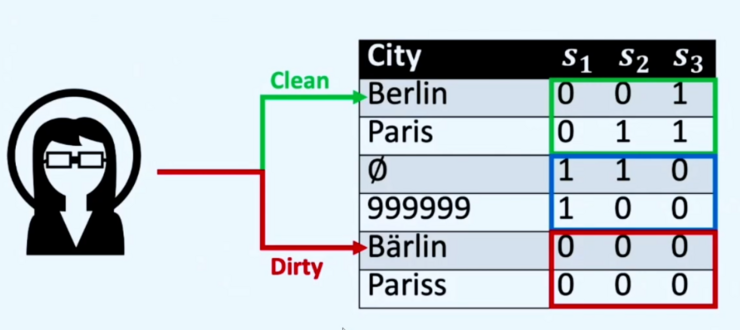
What is meant by Data Quality?
At its core, we're discussing errors, referred to as Data Errors, that degrade the quality of a dataset. These errors cover various types, including:
Integrity constraint violations, such as duplicate ID assignments. Representation mistakes, like incorrect ordering of first and last names. Column shifts, contradictions, missing, or even hidden missing values, which are values intentionally not disclosed by the user. Typos or even semantic errors.
Traditional Data Cleaning Approaches
There are four main categories of Traditional Data Cleaning approaches: Rule-Based Techniques, Pattern-Based Techniques, Statistical Techniques, and Masterdata/Knowledge base Approaches.
Pattern-Based Techniques are primarily used to ensure uniformity and fix syntactical representations such as dates, categories, and missing values.
Statistical Approaches can identify outliers, including infrequent string occurrences and numerical anomalies.
Master-Data/Crowdsourcing leverages high-quality data from knowledge bases or crowdsourced judgments to compare values.
Rule-Based Techniques employ rules, integrity constraints, and dependencies to ensure consistency in data. One Method involves parsing rules to create conflict graphs and intelligently clean most conflicting data until consistency is achieved. However, certain errors may lack defined consistency rules, making them uncleanable.
Where are we and what needs to be done?
Professor Abedjan and his colleagues identified two main findings during their literature review on Detecting Data Errors. Firstly, most research papers introduce their errors into clean data to test their methods, rather than using naturally occurring errors. Secondly, studies often compare tools within the same category.
They aimed to conduct a new case study to assess how error detection techniques perform in real-world scenarios and how combining these techniques affects their performance. The focus was on determining the most reliable approaches, rather than simply the best ones.
To achieve this, they utilized five real-world datasets to evaluate eight error detection methods for their effectiveness both individually and in combination. Metrics such as Precision, Recall, and F-Measure were utilized. Different approaches to combining tools were considered, such as whether all tools must agree on an error or only a subset. Depending on this, Precision or Recall may be preferred.
Some of the conclusions drawn include the absence of a single dominant tool, though effective ones exist. However, performance varies notably, and even combining all methods does not ensure consistent results. They discovered that making enhancements to individual methods leads to only marginal improvements, emphasizing the greater importance of prioritizing the combination of techniques.
In real-world scenarios, we prefer all-in-one tools. However, even with AI tools that require training and parameter tuning, users often need to define constraints they may not know or wish to create. Also, labeling 5% of a large dataset for training is unrealistic, especially when dealing with sensitive organizational data that can't be outsourced.
Example-based Cleaning
Example-based Cleaning aims to meet these requirements by allowing the user to specify what needs to be cleaned without dictating how it should be done. It is an approach that aims to autonomously detects and repairs data errors without requiring user-defined constraints, instead relying on minimal user labeling. But solutions for these problems are needed:
How to represent instances? Labeled typos may not cover all types, and the same value can be wrong or right depending on the context.
How to select instances? The dataset has a dirty-clean imbalance, making instance selection for labeling challenging. Also, all error types should ideally be labeled at least once.
How to model a classification task? Multiclass or generative? How to handle out-of-dataset corrections? Limiting solutions to existing values in the clean dataset may be problematic.
Professor Abedjan and his colleagues addressed these challenges by developing two tools for the Example-based Cleaning approach: Raha, dedicated to error detection, and Baran, responsible for managing the correction process.
RAHA
Raha is an Example-Based configuration-free system for Error Detection. It takes a Dirty Dataset and a few labeled Tuples as input and marks error data. Raha utilizes all categories of error detection tools in an ensemble. This raises the question again of how strategies should be combined:
Unsupervised strategies like Top k have a precision/recall tradeoff and exhibit poor performance. Semi-supervised for the best combination would be possible, but it requires training data for a classification task. In any case, individual tools and prediction models must always be tuned, which is not desired. Therefore, we have two goals:
We want to automatically generate algorithm configurations.
And we want to limit the number of labels - i.e., if an error type exists, it receives a label, not a set number.
Raha's Solution: Because we do not want to tune each tool/algorithm individually, Raha generates many configurations for each tool. Each configuration of an algorithm becomes its own error detection strategy. Each strategy marks data cells as error data or clean via a binary value. Raha then generates a feature vector for each data cell based on the respective outputs of the strategy. Using the feature vectors, clusters can be formed based on similarity. The cluster assumption is that data points in a cluster likely belong to the same label class. Once a data point is labeled in a cluster, label propagation can be applied to all data points in that cluster.