Data profiling refers to the activity of creating small but informative summaries of a database. ~ Ted Johnson, Encyclopedia of Database Systems
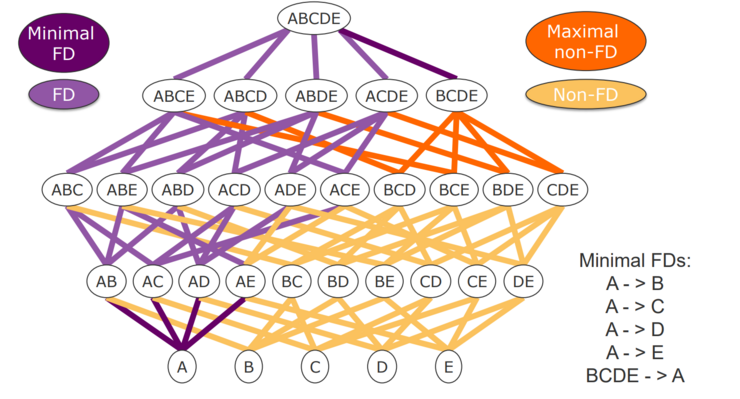
These data profiling activities can be classified into different kinds of tasks - single column, multiple columns, and dependencies. Single columns and multiple columns contain computationally rather trivial tasks like determining cardinalities, value distributions, correlations, or clusters & outliers. Dependencies, such as Unique Column Combinations (UCCs), Functional Dependencies (FDs), and Inclusion Dependencies (INDs) can be very costly to compute.
Use Cases
Data Profiling can be used in a variety of use cases. In query optimization, cardinalities, histograms, and counts play a crucial role in cost estimation and form a statistical basis on which a concrete query plan can be decided upon. In data cleansing patterns and rules found via data profiling can be used to identify violations. Dependencies that are found across multiple datasets can help in data integration processes. In database reverse engineering, Data Profiling is used to determine the underlying data model by helping to understand the relations between the entities. Data Profiling also serves as a prerequisite for data preparation.
Problems
Commercial and research tools are available for many data profiling tasks. Yet most are complex to configure or do not offer a convincing way to view and interpret the results. For example, IBM's Information Analyzer tool requires the user to input potential foreign candidates, which are then analyzed via an SQL query. Thus, there is no completely automatic discovery and the actual checking of the candidate is not very scalable, as a whole query is run even if there are violations found early on. Therefore, even if these tools support the required tasks, running them and interpreting their results can be very tedious.
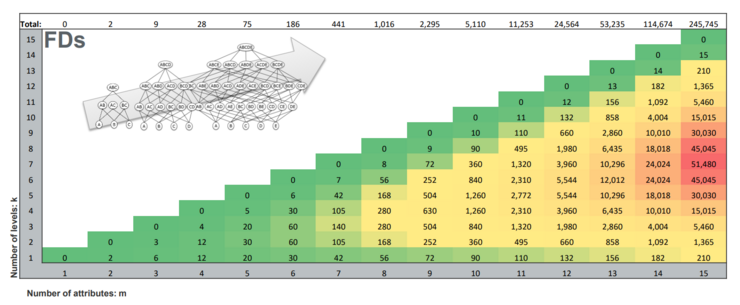
In Data Profiling one does not simply analyze single columns, but instead looks at multiple column combinations, e.g. column A depends on columns B, C, and D. To check every key candidate combination of a table with 100 columns, 1.3 nonillion column combinations would have to be checked (a number with 31 digits). This is because the number of column combinations grows exponentially to the number of columns (2^n - 1). Data Profiling tasks can thus, at least theoretically, be computationally highly expensive.
Uniqueness, Keys, and Foreign Keys
Unique Column Combinations (UCCs) are combinations of columns for which every value combination of the specified columns is unique.
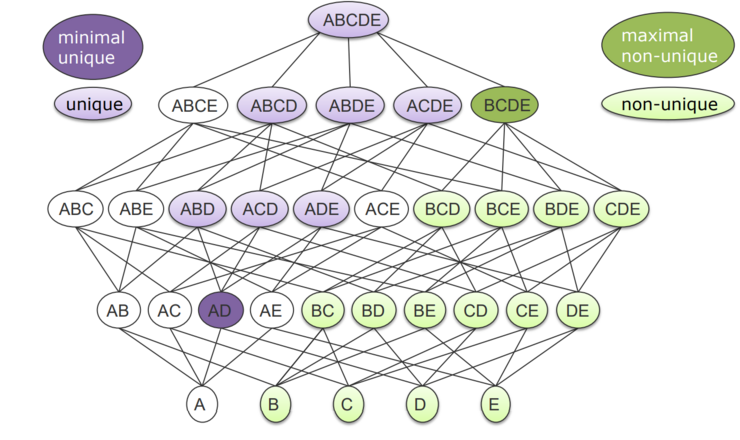
While in the given table, neither A nor B are unique themselves, their combination (A, B) is considered an UCC, as no value is present twice. An UCC is considered minimal if there is no unique column subset. Minimal UCCs are often used to determine key candidates (with the addition of containing no null values).
Lattice
The number of candidates grows exponentially to the number of columns (2^n-1). Thus, the task of finding all UCCs is often reduced to finding all minimal UCCs. Given a minimal UCC, we can "reconstruct" all UCCs by simply adding new columns to the minimal UCCs, as that does not affect the Uniqueness. A maximal non-unique combination, on the other hand, is a combination that becomes a UCC once a new column is added. All subsets of a (maximal) non-unique combination are also non-unique.
To efficiently work on or visualize UCC discovery, a lattice can be used. A lattice is a partially ordered set, where each set of elements has a unique supremum (union) and infimum (intersection). Visualization of lattices is done using Hasse diagrams, where each element is a node and its edges go upward, to the smallest larger element(s).