If we receive data without an accompanying schema, we have the ability to extract a schema directly from the data itself. Then, we can perform containment-checking by comparing these extracted schemas. Current advanced methods for schema extraction focus mostly on understanding the structure of JSON data [4], like how it's nested and whether it contains arrays or objects. Professor Scherzinger and her team, however, are working on identifying 'tagged unions' within JSON Schema. Tagged unions are a design pattern in JSON Schema where a specific property within an object (referred to as the tag) suggests different subschemas for the other properties in the object based on its value. The team aims to formalize these relationships as conditional functional dependencies and represent them using the JSON Schema operators 'if-then-else'. [5, 6]
Extracting JSON Schemas with tagged unions [6]
Conclusion
JSON Schema is widely used in various fields, such as NoSQL document stores for validating inputs, Web APIs for ensuring correct data formats and interactions, and in the creation of forms based on JSON data. This broad application spectrum highlights the versatility and importance of JSON Schema in managing and validating data across different technological domains.
Prof. Dr. Stefanie Scherzinger's research focuses on advanced JSON Schema applications, including witness generation algorithms and containment checks. She explores schema extraction, particularly identifying tagged unions in JSON Schema. Her work also involves addressing machine learning pipeline issues through early error detection using JSON Schema reasoning. Additionally, she is contributing to the development of JTutor, a JSON Schema validator, and has made significant advancements in debugging and accuracy in schema validation.
Resources
[1] Lecture "Detecting Data-Code Mismatches in Machine Learning Pipelines" (tele-task.de)
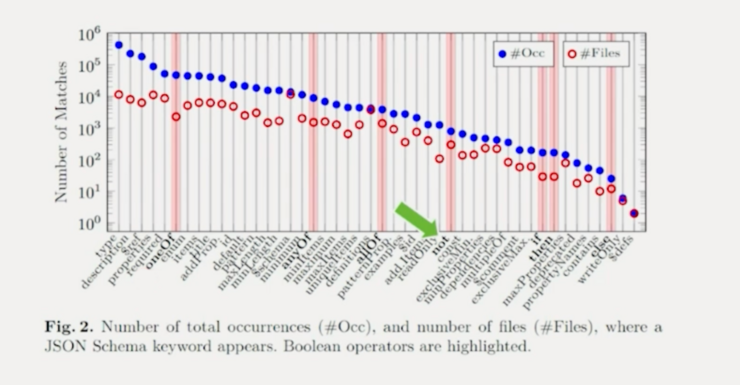
[2] An Empirical Study on the “Usage of Not” in Real-World JSON Schema Documents (link.springer.com)
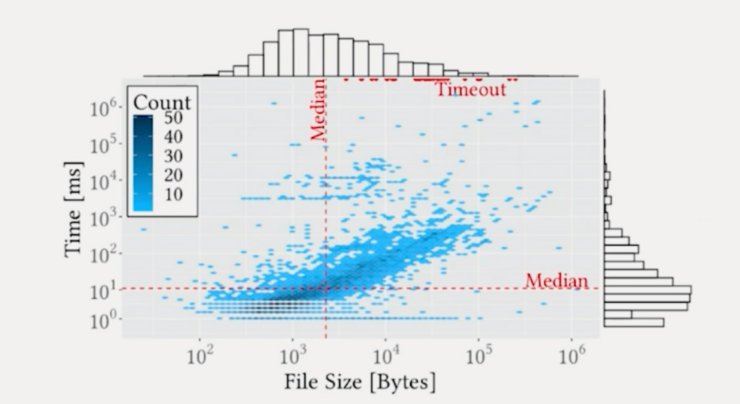
[3] Witness Generation for JSON Schema (arxiv.org)
[4] Schema Extraction and Structural Outlier Detection for JSON-based NoSQL Data Stores (researchgate.net)
[5] Tagger: A Tool for the Discovery of Tagged Unions in JSON Schema Extraction (uni-regensburg.de)
[6] Extracting JSON Schemas with Tagged Unions (arxiv.org)