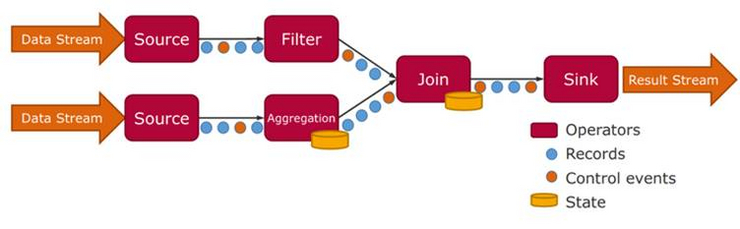
Figure 1: Conceptual visualization of a stream processing job [6]
Usage and benefits of stream processing in the real-world
The need for hardware optimization can be demonstrated by looking at Singles’ Day at Ali Baba in 2020. On November 11, Ali Baba processed over four billion records per second using Apache Flink [1]. As Apache Flink is a scale-out system, more queries require more servers. Therefore, Ali Baba utilized 1.5 million 16-core CPUs, costing approximately $1 per hour. The company deployed close to 93,750 virtual machines, costing approximately $2.25 million this day. Each virtual machine received approximately 42 thousand events per second.
By using scale-up research stream processing hardware systems, Ali Baba could have processed over 100 million events per second per machine. The company could have saved $2 million by using 52-core instances at a cost of approximately $6 per hour. The cost would have been around $5,760 per day.
The Iterator and the Query Compilation Model
There are multiple modes of processing data in a database system. The benefits and considerations that influence the appropriateness of any approach differ wildly between classical and stream processing systems. The iterator model looks at each event individually and pushes it through the predefined pipeline [3]. Therefore, it has many virtual method calls and poor cache locality for data and code. For that reason, Apache Flink, which uses the iterator model, is slow compared to research systems. To improve efficiency, a query compilation model can be used instead [4]. The query compilation model consists of a diminutive program that includes all essential operators and is compiled into a single, compact binary. The resulting software has good cache locality and few to no virtual method calls.
Aspects of stream processing research
First, as data is processed incrementally rather than in batches, applications can differ from traditional database systems. Engaging with and experimenting with these novel application domains can facilitate the acquisition of valuable insights.
Second, research can be done at the operator level, looking at how aggregations and joins can be done efficiently in stream processing. As a result, organizations may be able to use resources more cost-effectively and sustainably.
Third, research may examine the semantics of the stream. This is helpful when dealing with large amounts of data, while waiting for an event to happen or any input to occur.
Last, execution strategy research can be done to improve query execution through multi-query processing. In addition, hardware optimization can be performed by developing and using novel available hardware.
SIMD compiler intrinsics
What is Single Instruction Multiple Data (SIMD)?
Today's CPUs have multiple cores that execute multiple instructions per cycle. To process multiple data objects in parallel, the single instruction multiple data (SIMD) registers within each core can be utilized [2]. These registers perform the same operation on multiple data points simultaneously.
What’s the problem with the current SIMD?
Most processor types currently have different instruction sets. The correct utilization of the corresponding concrete instruction set for any given processor can speed up table scans, hash tables, and sorting within a database. As each instruction set requires its own SIMD code, the resulting code is difficult to test, develop, and benchmark. Therefore, SIMD code is not often used. More regularly, the application code is translated into SIMD intrinsics using a library. These intrinsics are translated into a compiler representation, which is then compiled into assembly [2].
To improve performance, compiler intrinsics can be used directly instead of application code [7]. SIMD intrinsics can be written using GCC vector extensions. The compiler will then take care of the platform-specific instruction selection.
The efficiency of this approach is benchmarked by unpacking packed 9-bit integers to 32 bits using shuffling and shifting [2]. As shown in Figure 2, on average, the handwritten code will be slower than the vectorized code. As of now, there are certain edge cases, for which the SIMD compiler intrinsics do not work well because certain operations are not supported.