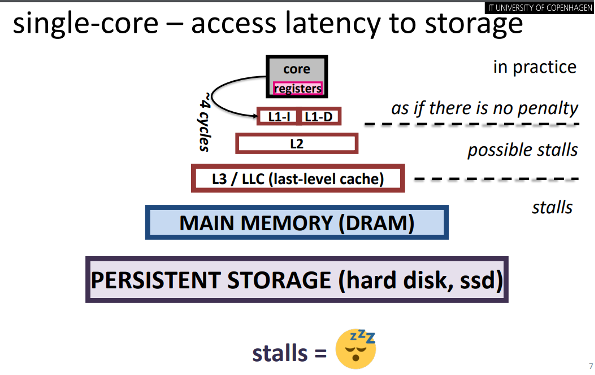
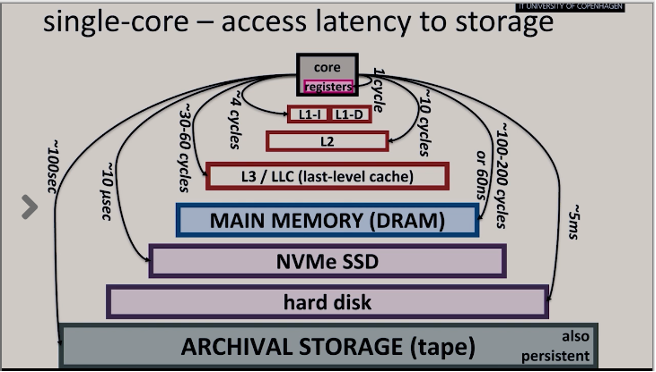
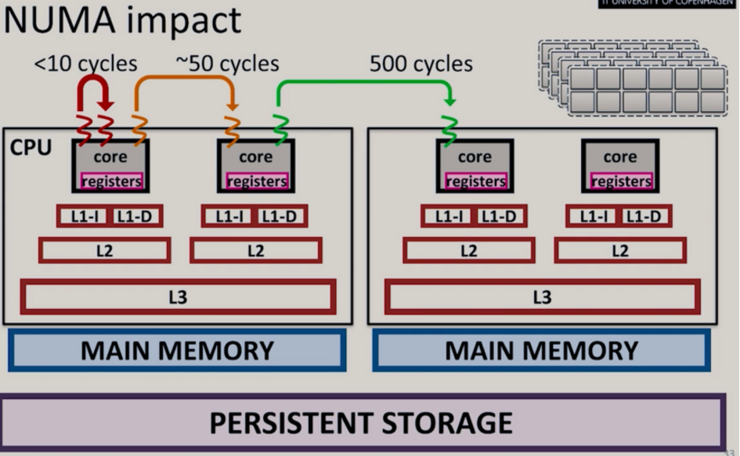
Today's computers have more and more CPU cores. Coordinating jobs to run in parallel on several cores is therefore more important than ever in order to utilize the full computational power.
Prof. Pinar Tözün – associate professor at the IT University of Copenhagen - gave a lecture about "Hardware Parallelism & Transaction Processing Systems", which examined exactly this problem with focus on online transaction processing. This blog post summarizes the key points based on this lecture.
Before we dive into the topic, it is worth mentioning, that online transaction processing (OLTP) is only a subset of data processing systems, where short-running, atomic (indivisible and irreducible) operations, called transactions, are processed. A typical example for OLTP are bank transactions or booking systems. OLTP systems have usually a lot of transactions of limited types, where each transaction is only accessing a very limited amount of data. Online analytical processing (OLAP), on the other hand, is characterized by long-running requests, each accessing a lot of data. Typical use cases are complex analysis, e.g. forecast planning, data mining or business intelligence applications. Both types of processing have their individual characteristics, therefore only OLTP was considered in the lecture and this blog post.
Background
CPU generations
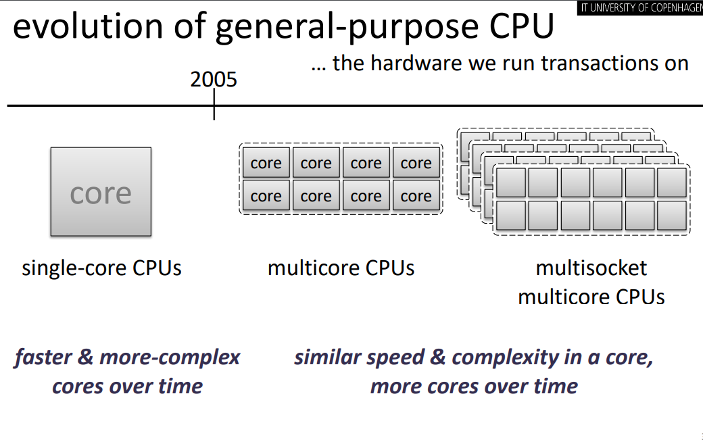
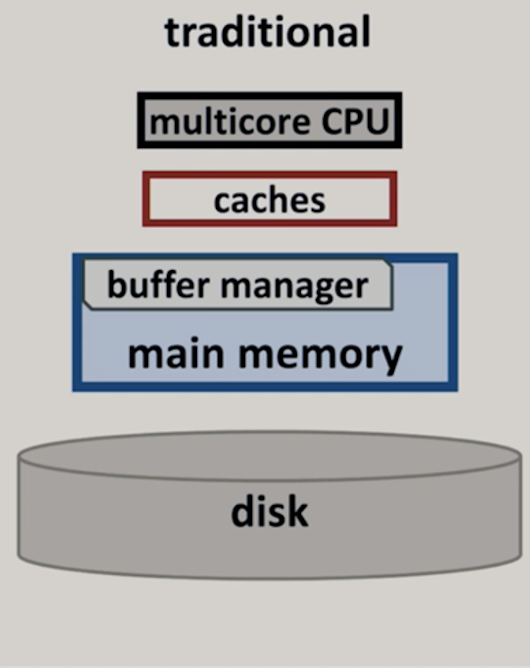
General purpose CPUs – the hardware we run the transactions on – had drastically evolved in the last decades from single-core CPUs to multicore CPUs and then to multicore multisocket models. As shown in the figure below, single-core CPUs utilize faster & more complex cores over time, which reached its limits around 2005, when multicore CPUs were built to further increase the performance by utilizing more cores with the same speed and complexity.