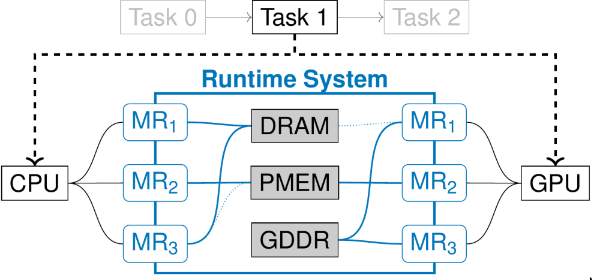
Fig.3 - Abstraction layer exposing different memory regions.
8.2.2. Typed Memory Regions
Each memory region can also be typed based on its use case. The speaker proposes global state, global scratch, and private scratch. The global state is used for coherent and synchronous communication. Exchanging data can be done asynchronously and coherently and would be typed as a global scratch. Local computations should be typed as private scatch.
Different dataflow systems can map their operations into these typed memory regions based on their purpose and properties. DBMS operations for synchronization would be typed as global state, while the input data for ML and AI can typed as global scatch.
8.2.3. Control Plane Tasks
Switching to the control plane, Prof. Dr. Jana Giceva mentions basic memory region ownership schemes, like singular, transferred, or shared ownership. Managing the ownership is essential to avoid data movement or copying. Secondly, the control planes manage the lifetimes of the memory regions. Therefore, garbage collection needs a lightweight metadata system to keep track of the usage of memory regions. Further tasks like resource monitoring and deployment are assigned to the control plane.
9. Conclusion
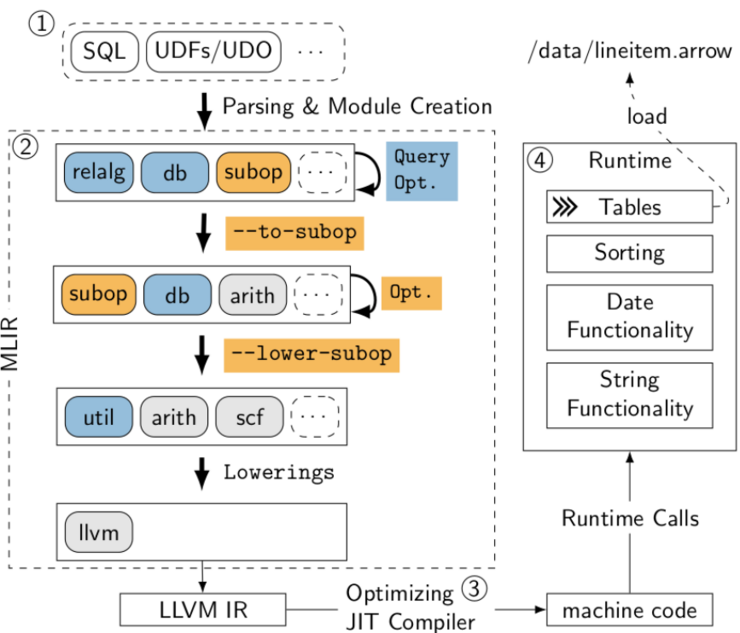
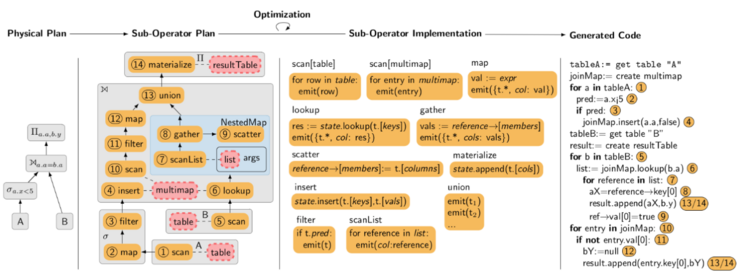
In the presentation by Dr. Prof. Jana Giceva, the main goal of making future-proof data processing is achievable by an open compilation and optimization framework. The proposed ideas add abstraction layers; however, the approach avoids a trade between higher abstractions and performance.
The central concept relies on whiteboxing the optimization and compilation framework by making them more interchangeable in each step by adding declarative suboperators and intermediate formats. The research prototype LingoDB implements the ideas presented. Its comparison with DuckDB, Hyper, and Umbra shows that a hardware-agnostic data processing system with carefully crafted abstraction layers still achieves competitive performance while increasing flexibility and extensibility.
The last topic of her presentation covered a request for blackboxing the underlying hardware to be independent of the rapid evolution of these; she introduced a memory-centric system. Her proposal offers an abstraction for selecting the correct memory type based on declarative attributes.
10. References
[1]
Jana Giceva, Gustavo Alonso, Timothy Roscoe, and Tim Harris. 2014. Deployment of query plans on multicores. Proceedings of the VLDB Endowment 8, 3 (November 2014), 233–244. https://doi.org/10.14778/2735508.2735513
[2]
Michael Jungmair and Jana Giceva. 2023. Declarative Sub-Operators for Universal Data Processing. Proceedings of the VLDB Endowment 16, 11 (July 2023), 3461–3474. https://doi.org/10.14778/3611479.3611539
[3]
Michael Jungmair, André Kohn, and Jana Giceva. 2022. Designing an open framework for query optimization and compilation. Proceedings of the VLDB Endowment 15, 11 (July 2022), 2389–2401. https://doi.org/10.14778/3551793.3551801
[4]
Kaan Kara, Jana Giceva, and Gustavo Alonso. 2017. FPGA-based Data Partitioning. In Proceedings of the 2017 ACM International Conference on Management of Data (SIGMOD '17), May 2017. Association for Computing Machinery, New York, NY, USA, 433–445. https://doi.org/10.1145/3035918.3035946
[5]
Alfons Kemper and Thomas Neumann. 2011. HyPer: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots. In 2011 IEEE 27th International Conference on Data Engineering, April 2011. 195–206. https://doi.org/10.1109/ICDE.2011.5767867
[6]
Chris Lattner, Mehdi Amini, Uday Bondhugula, Albert Cohen, Andy Davis, Jacques Pienaar, River Riddle, Tatiana Shpeisman, Nicolas Vasilache, and Oleksandr Zinenko. 2021. MLIR: Scaling Compiler Infrastructure for Domain Specific Computation. In 2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), February 2021. 2–14. https://doi.org/10.1109/CGO51591.2021.9370308
[7]
Darko Makreshanski, Jana Giceva, Claude Barthels, and Gustavo Alonso. 2017. BatchDB: Efficient Isolated Execution of Hybrid OLTP+OLAP Workloads for Interactive Applications. In Proceedings of the 2017 ACM International Conference on Management of Data (SIGMOD '17), May 2017. Association for Computing Machinery, New York, NY, USA, 37–50. https://doi.org/10.1145/3035918.3035959
[8]
Thomas Neumann and Michael Freitag. Umbra: A Disk-Based System with In-Memory Performance.
[9]
Mark Raasveldt and Hannes Mühleisen. 2019. DuckDB: An Embeddable Analytical Database. In Proceedings of the 2019 International Conference on Management of Data (SIGMOD '19), June 2019. Association for Computing Machinery, New York, NY, USA, 1981–1984. https://doi.org/10.1145/3299869.3320212