Goal, Problem, Solution
The talk discusses several projects that aim to improve the performance and (especially) the robustness of Query Optimization. While there are a multitude of good proposals to improve Query Optimization (i.e. with machine learning), many struggle with dynamic data, changing database schemas and consistent performance. The speaker introduces 4 different projects that approach these issues by looking at cardinality estimation (estimating the size of intermediate results), machine learning and better infrastructure for the development and testing of Query Optimization.
Background
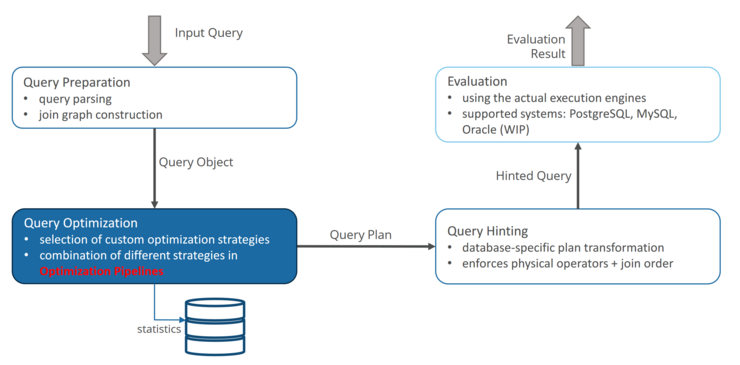
The speaker started by explaining the rudiments and relevance of the optimization of Query Processing. First, Lehner introduced the basic steps of the process of query-processing:
- Generating a Logical Query Plan
- Rewrite and Transformation
Logical Query Plan
Step one is concerned with the optimization of a given query without considering the underlying hardware. It only regards the transformation of a query (which is basically a string) to a logical query plan. This includes checking, if the query is executable at all (Integrity Control) by looking at its structural integrity as well as checking whether a given user has access to the data needed to fulfill the query (Access Control). At the beginning of the process we have a query (like „SELECT X FROM Z“) and at the end we have a plan in the form of relational algebra, consisting of operations like join, selection etc.
Rewrite and Transformation
Step two is concerned with the optimization of the query plan derived from step one as well as transforming the plan into a Query Execution Plan. The latter is on the hardware level and the relation is similar to that of the relation between plain Java-Code and compiled Java-Code, meaning it contains instructions targeted at the physical layer, implementing the optimized Query Plan. It is to note that there might not be a one-to-one relationship between a logical operator and a physical operator (i.e. a logical operator might be implemented using many physical operators).
Are we polishing a round ball?
The speaker then poses the question, whether Query Optimization is a done deal since it has been researched since the early 1970s. The field contains a lot of research and many strategies (i.e. for join ordering) are well known and implemented. Lehner then answers the question by reframing the question of modern query optimization approaches: „Is it actually a ball?“.
The world is polystore
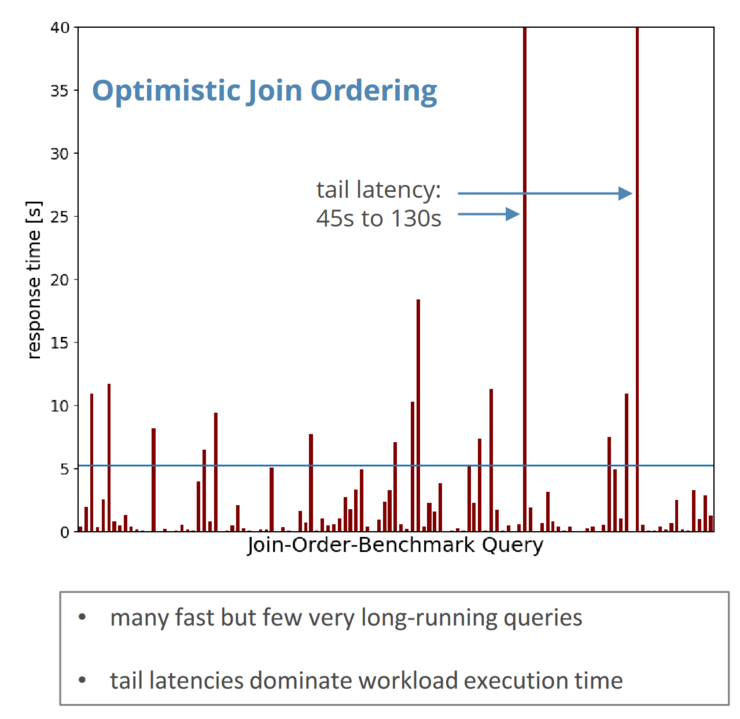
The environment of Database-Operations has changed greatly in the last decades. The speaker explains that even the application side of things has become very complex. Not only do we have to deal with very complex data-structures (no flat tables, inheritence hierarchies etc.), nonrelational data (no or no rigid schemas like json, XML, Graphs), and the sheer size of Databases. Lehner expounds that nowadays even a medium sized Database might contain 100.000 database objects. This results in very complex queries that contain multiple (10 to 20) joins. The problem this poses for Query Optimization is the fact that the performance of “traditional '' Optimization strategies varies greatly is therefore nor reliable and lead to tail latencies. When comparing the response times of different database queries, one will notice that most queries can be processed very quickly. The response time for a few inquiries, however, takes much longer. In one example (shown in Figure 1) this leads to tail latencies of 45 up to 130 seconds while most response times are well under that.