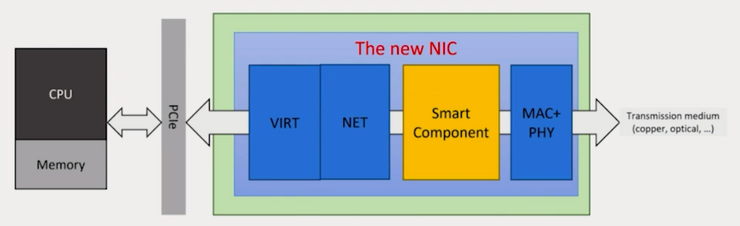
A way to make further scaling possible is reducing the data center tax using specialized network devices. Offloading some processing to the NIC allows freeing up CPU cycles. Zsolt István presents two examples where this was successfully done.
Azure Accelerated Networking
Cloud providers have to apply many networking rules to ensure security, flexibility, performance and isolation. There needs to be some virtualization of the networking to ensure that each virtual machine thinks they are alone.
To achieve this in the Azure cloud, Microsoft's software defined networking (SDN) execution required several CPU cores. To avoid this, they developed specialized hardware. Their SmartNICs combined regular network processing with programmable SDN rule evaluation. The per-flow rule execution was offloaded to the network card, which reduces CPU overhead. The result was an overall lower latency, higher bandwidth and increased efficiency thanks to specialized hardware.
Since 2015 Microsoft has deployed this technology in all new servers. There are now millions of machines using accelerated networking in azure. Today, the same hardware is also used by Microsoft to offload some machine learning operations.
SQL Filter Offloading
In disaggregated architectures, the storage is often attached via network. Many applications can avoid moving all data to the compute layer. Some operations where this is possible are common enough to be improved by specialized networking hardware at the storage level. This reduces network overheads while also reducing CPU requirements and allows for more predictable performance.
One example where this technology was commercially used is Amazon AQUA. In his talk, Zsolt István explains the technology using Caribou as an example. Caribou is a distributed storage solution that he helped develop and which works similarly as AQUA.
Caribou allows pushing down filter operations in SQL queries to the storage layer. There they are executed by specialized hardware that enable processing at "line-rate". This term means that the computation is at least fast as the network speed and never slows down retrieval. In hardware, the algorithms can be re-designed to become bandwidth bound instead of compute-bound.
Overview of the design space
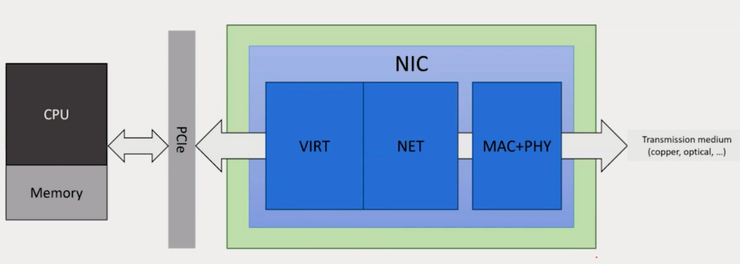
After understanding the problem that motivate the use of SmartNICs and seeing these examples of their successful use, there remain open questions of when and how we can design SmartNICs. To answer them, we start by taking a look at how a conventional NIC works.
On a very basic level, a NIC translates between physical signals (like changing voltages on a wire) and in-memory representation of data. It consists of three logical layers:
- Virtualization / Steering layer: Controls how data is sent to the cores that need it and how the interface is virtualized (e.g. Open vSwitch support)
- Network layer: Controls how nodes are identified and how they talk to each other (e.g. IPv4, IPv6)
- Physical layer: Controls how bits are encoded on the transfer medium (e.g. Ethernet)