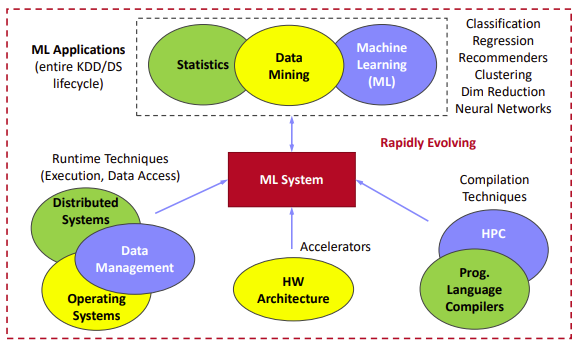
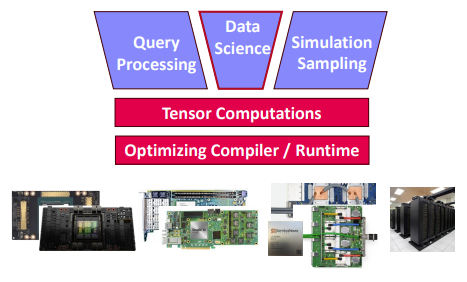
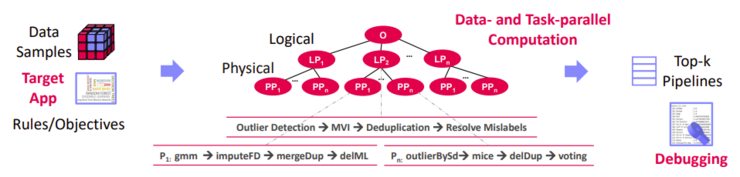
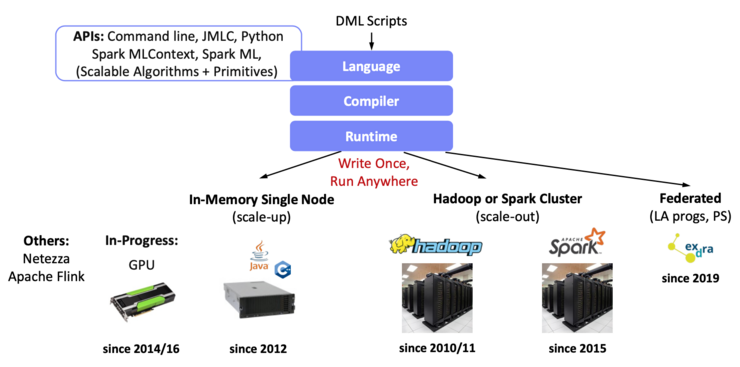
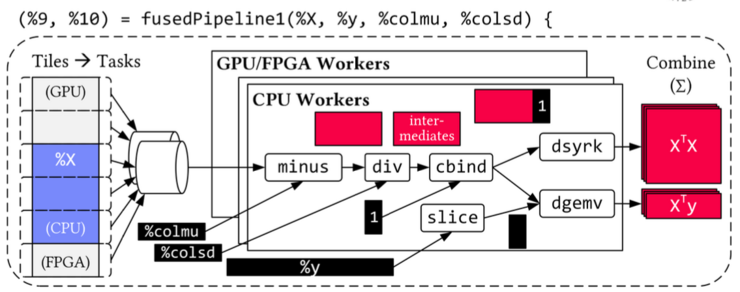
The optimizing compiler translates hardware-independent DML scripts to hybrid query plans in a “Write once, run anywhere” fashion.
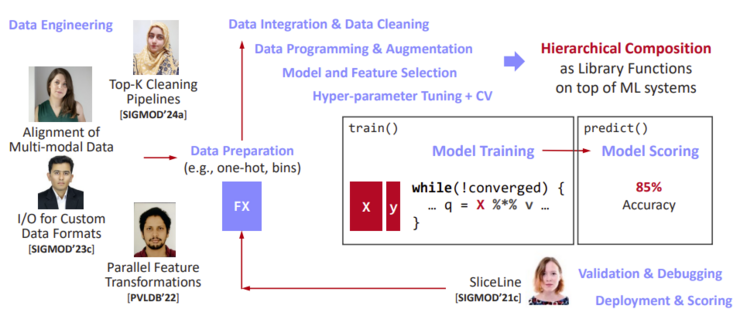
It was forked from IBM's open-sourced SystemML that went through the Apache Incubator to an Apache Top-Level Project. The fork was rescoped to meet the end-to-end data science lifecycle requirements and was later invited to be merged back into SystemML, which was then renamed to SystemDS. Serving as an umbrella project, SystemDS integrates research efforts. It introduces built-in functions through its domain-specific language, offering users enhanced abstractions and routing to superior algorithms, with the compiler efficiently collapsing these abstractions into efficient execution plans.
2. Multi-level Lineage Tracing & Reuse
To enable multi-level lineage tracing and reuse in data-centric ML pipelines, the framework dynamically traces the lineage during the execution of individual operations, capturing the provenance of how intermediate results were computed, even in the cases of non-determinism. A lineage graph is constructed for every live variable, providing a comprehensive representation of the sequence of operations involved and offering insights into the computational history of variables. The generated lineage graph can be serialized into a log, enabling easy sharing and collaboration among team members to simplify debugging by capturing the entire history of computations leading to specific results. Furthermore, the serialized lineage graph can be deserialized and used to reconstruct the program, ensuring that it yields the same intermediates with the same inputs, including stored seeds, thus fostering reproducibility. This approach not only enables full reuse of intermediates, eliminating the need for redundant computations but also allows for selective partial reuse. Particularly valuable in scenarios where larger models were already trained for some features, partial reuse facilitates training additional features without recomputing the entire model, optimizing computational efficiency in data-centric ML pipelines.
3. Compressed Linear Algebra Extended
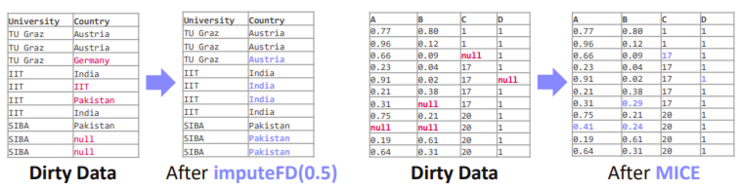
Compressed Linear Algebra Extended plays an essential role in data-centric ML pipelines. By introducing a sophisticated lossless compression framework across multiple tiers, it addresses the challenge of accommodating large datasets into memory. This versatility extends to single-node configurations, distributed clusters with distributed caching, and hardware accelerators. Notably, the system executes linear algebra operations directly on the compressed data representation, similar to query processing on compressed data structures. Emphasizing redundancy exploitation, it efficiently manages both data redundancy, exemplified by distinct values, and structural redundancy, evident in recurring patterns within the data. Operating in a workload-aware manner, the system chooses its compression strategy based on user scripts executing linear algebra primitives. When data fits into memory, a lighter compression is applied to enhance computation speed, while stronger compression is utilized when data exceeds cache capacities for optimal caching efficiency. An example of such compression is dense dictionary coding, a technique adept at encoding data, reducing redundancy, and improving compression ratios.
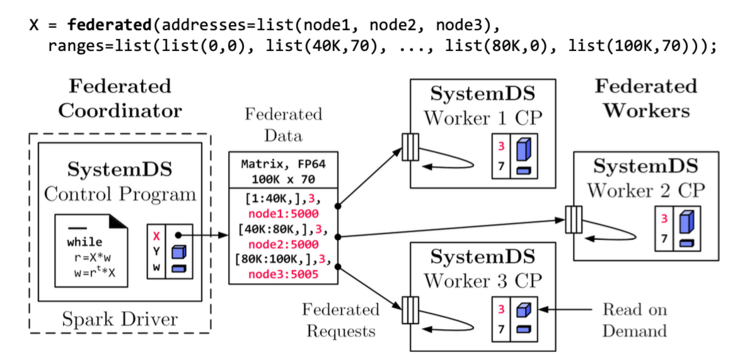
4. Federated Learning in SystemDS
Federated Learning in SystemDS emerged as a collaborative project involving Siemens, DFKI, TU Berlin, and other contributors. It enables the training of machine learning models and complete end-to-end data science pipelines on federated data. In this paradigm, data remains securely with its owners, ensuring data ownership and privacy. Matrix representations adopt a federated metadata object approach, distributing slices of matrices across different nodes. The implementation allows iterative machine-learning algorithms to run seamlessly. When operations are executed on these federated metadata objects, subqueries are initiated on corresponding servers and their federated workers. These workers execute computations on data, calculate, and return intermediates, which can be retained for future operations and follow-ups.