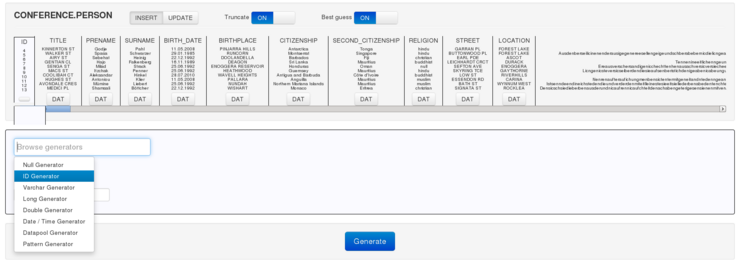
PopulAid is a tool to generate customized data for application testing. Via a convenient web interface, developers can easily pick their database schemas, assign generators to columns, and get immediate previews of potential results. In doing so, generators consider not only specific value properties for one column such as the data type, ranges, data pools, distributions, or the number of distinct values, but also keep foreign keys, allow for pattern evaluation and fulfill dependencies for column combinations. PopulAid allows developers to create data in a scalable and efficient manner by applying these generators to SAP HANA.
The tool aims to seamlessly integrate data generation into the development processes by ensuring good usability. To achieve this goal, we focus on three core concepts:
No setup required. When available, PopulAid is aimed to be shipped together with the target database SAP HANA.
Immediate feedback of the input via a preview of the values to be generated.
Assistive guessing of suitable generators. Especially for wide tables with more than 100 columns, assigning generators manually is tedious. Guessing of suitable generators for missing columns is done on the basis of the present datatype, the name of the column, and past generation tasks.