We compare a) a single database node with b) a multi-node setup consisting of a master node (current/actual data only), one replica node of the master for running OLAP transactions, and a cold node for historical data. Both setups have an equal total amount of cores and main memory. The usage of the replica node can be switched on and off. The workload consists of three types of transactions (ratio configurable): invoice postings (sFIN-adapted), read-only transactions incl. transactional queries (incl. BKPF-BSEG-joins), and OLAP transactions incl. read-heavy analytical queries.
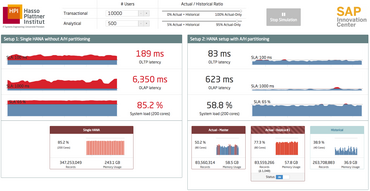
With the partitioning into current and historical and replication of the current data, we see the following improvements (90% current-only OLAP transactions, 100% current-only OLTP transactions, one of 100 queries being analytical):
Improved performance
Transactional processing is improved even without the use of a replica due to the smaller data set. Activating the replica, the multi-node setup is faster by a factor of up to 4x for mixed workloads.
The higher the skew is towards an current-only workload, the more the new architecture outperforms the traditional setup.
- When adding analytical users to the system, a replica of the current master node lowers the latency of OLTP transactions due to better load distribution.
Reduced costs
Historical data can be purged and better compressed to decrease the memory footprint and require less main memory than the traditional setup with all data being memory-resident.
Overall system costs potentially decrease as smaller servers for the historical nodes can be deployed, hence avoiding disproportional prices for large server systems.