In recent years, rapid advances in location-acquisition technologies have led to large amounts of time-stamped location data. Positioning technologies like Global Positioning System (GPS)-based, communication network-based (e.g. 4G or Wi-Fi), and proximity-based (e.g. Radio Frequency Identification) systems enable the tracking of various moving objects, such as vehicle, people, and natural phenomena. A trajectory is represented by a series of chronologically ordered sampling points. Each sampling point contains spatial information, which is represented by a multidimensional coordinate in a geographical space, and temporal information, which is represented by a timestamp. Additionally, an object identifier assigns each sampling point to a specific moving object and the corresponding trajectory. Thereby, the duration and sampling rate depend on the application.
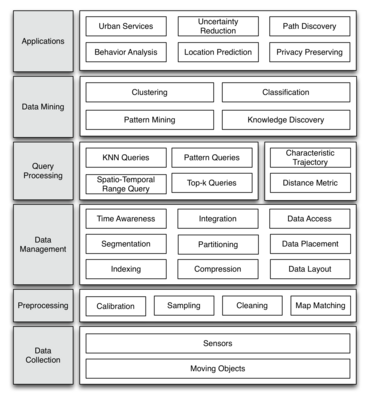
The trajectory data is collected from various moving objects with sensors by using the already mentioned location-acquisition technologies. To gather insights for different applications, the trajectory data has to be processed. This process can be classified in four layers, which are preprocessing, data management, query processing, and data mining. It strongly depends on the requirements of the application and the collected data, which steps of the different layers have to be performed during the trajectory mining process. The preprocessing step attempts to improve the data quality. Data management tackles the topic of storing large-scale trajectory data in an efficient and scalable manner. The next steps focus on the retrieval of appropriate data from the underlying storage system and to provide trajectory-based metrics for the next layer in the framework, which list several important mining techniques on spatio-temporal data.